Building Towards End-to-End Machine Learning Autonomy: Improving Multi-Object Tracking with a Single, Unified Model
In autonomous driving, multi-object tracking is a fundamental component that identifies, locates and follows all the relevant objects in the driving scene. Unlike object detection, which simply finds objects in a single frame, the tracking module assigns and maintains a unique ID for each object as they move in the scene over time. Essentially, it forms a trajectory for each object, and provides a continuous, real-time understanding of the vehicle’s surroundings to ensure safe and effective driving.

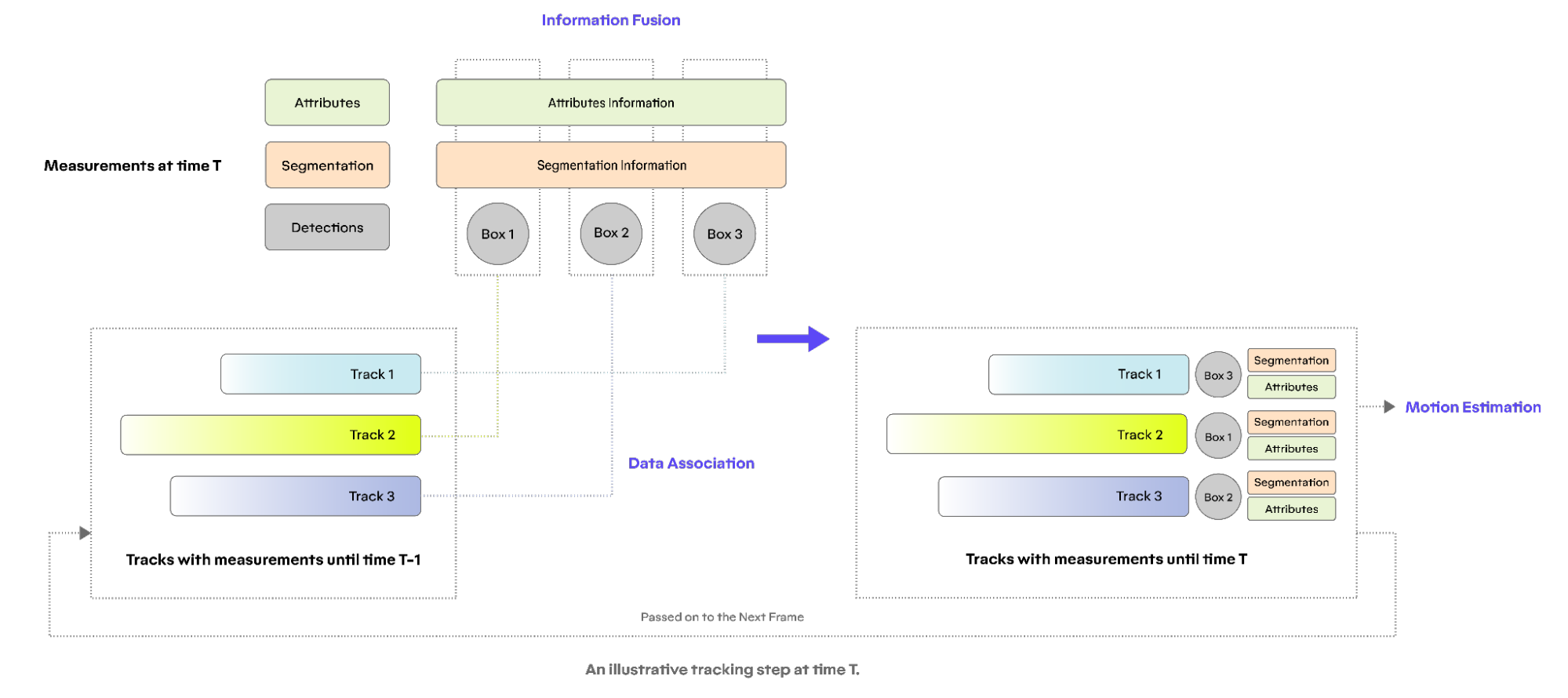
As illustrated in the above diagram, the tracking module stands in between the detection and prediction tasks. It has the following three basic components.
Information fusion: Combining abstracted information (such as detections, segmentations, fine-grained attributes) coming from the upstream detection system.
Data association: Linking detections (which happens at each individual time frame) over time to form a coherent understanding of each object's trajectory.
Motion estimation: Providing motion estimation (such as position, velocity, acceleration, etc) for each track in the system.
From Traditional Approaches Towards End-to-end Tracking
There are many traditional approaches to handle the tracking task under different scenarios and assumptions. For example, one of the most popular approaches is the Kalman Filter and its multiple variants, which estimates an object's state by recursively predicting its future motion based on a dynamic model and then correcting that prediction with noisy sensor measurements. However, they rely on the basic assumption of the first order of the Markov chain, meaning the system's current state depends only on the immediate previous state. This one-step dependency can be insufficient for complex scenarios, and we’ve seen such failures of the tracker module in situations like detection errors or occlusions.
On the other hand, ML-based approaches work by learning and adapting from existing data patterns, which help them overcome the core limitations of traditional approaches as mentioned above. For example, we could design an ML model for each of the tracking components (information fusion, data association, and motion estimation). At real time, those models are run sequentially, with some processing in between to feed the outputs from a previous model into the inputs of the next model.
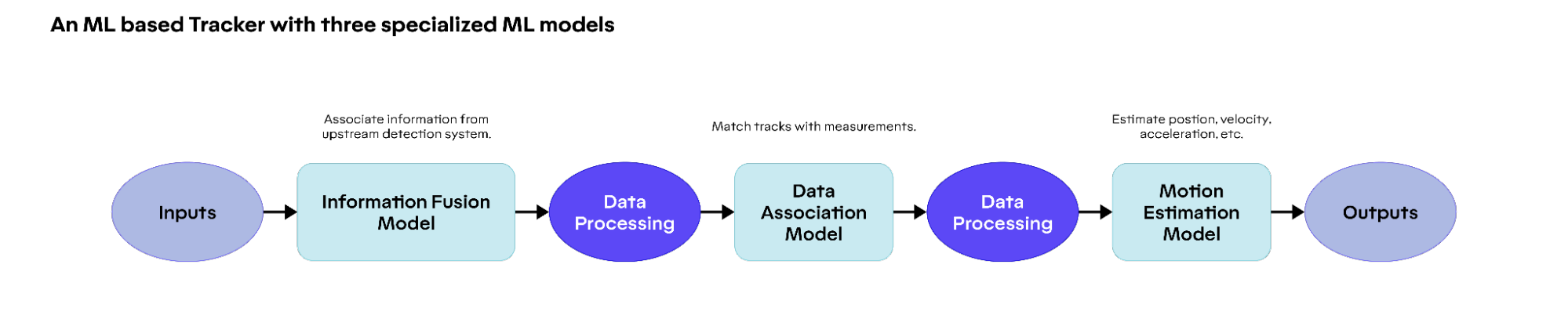
At Motional, we take one step further by designing an end-to-end tracking model, which includes all the above components into one unified model. At real time, the AV system will only need to run inference once, and will have the results for all the tracking components. Compared to multiple individual models, an end-to-end approach has the following advantages.
- No Information Loss. With multiple sequential models, low-level information from a previous model must first be processed into selected high-level features, go through a non-differentiable data processing step, before being sent into the next model. Information loss happens in both directions (forward and backward propagation) during this process. On the other hand, a unified model makes this information flow end-to-end, where the model learns un-interrupted signals from all the components.
- Feature Sharing. Although designed for different purposes, all the components could actually share some common features. For example, the context features learned in a data association task could also be used for motion estimation. With an end-to-end model, those features could be shared, so that the model is not only easier to learn, but will have more capacity for other features as well.
- Reduced Latency. An end-to-end system only needs to run inference once, and it also saves the intermediate processing steps. Those advantages translate into reduced system latency, quicker system response time in terms of emergency, and a safer AV system.
- Less Maintenance Overhead. In the AV space, new challenges kick in frequently, which often requires retraining of existing models to adapt to new scenarios. This process often involves a sequential retrain process when downstream models could be affected by the new output distributions of upstream models as an effect of the retrain. With fewer sequential models, the unified paradigm simplifies the maintenance process, and reduces the response time to deal with new on-road problems.
Unified Tracker: An End-to-end Tracking Model
Our unified tracking model includes all the tracking components mentioned above. Below shows a high-level diagram of the model architecture.
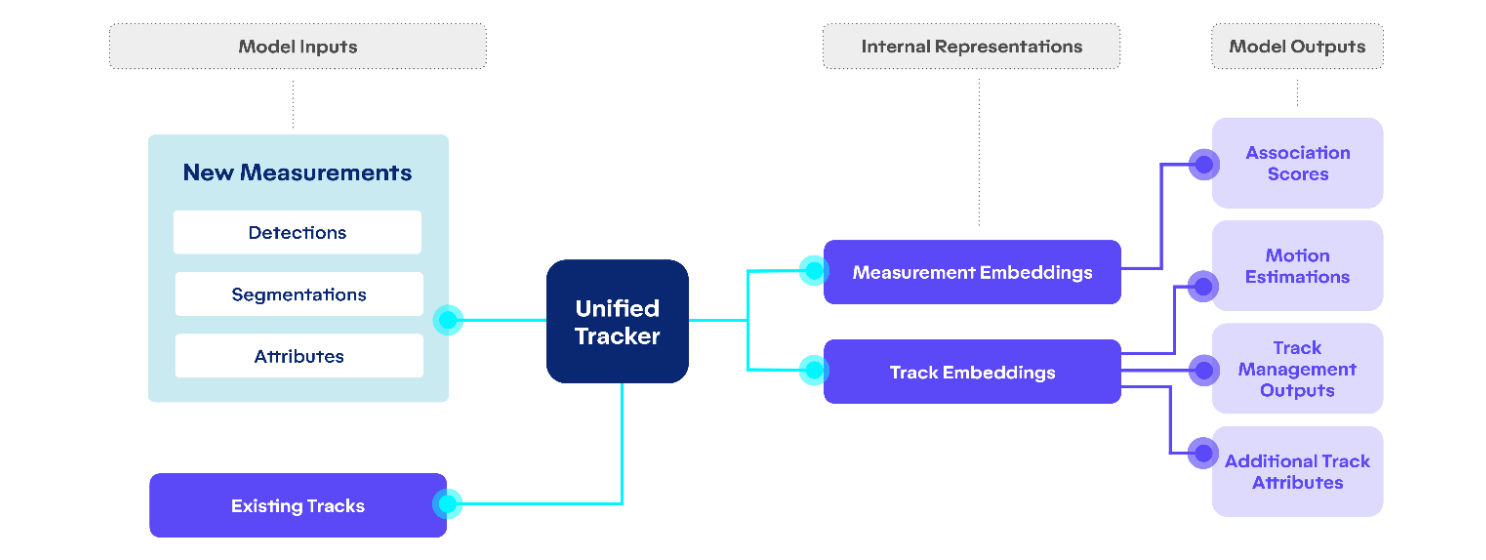
A Transformer-based Unified Model
Our unified tracker model utilizes the transformer architecture to allow for information sharing between multiple measurements and identified objects.
Self-attention. Self attention is performed among objects in the scenario, so that each object understands its surroundings. Those learned surrounding information is summarized as high-level feature vectors, which help improve the overall performance.
Cross-attention. Cross attention is performed between objects and new measurements so that each object understands which measurements to focus on. It allows for more efficient information sharing between existing objects and new measurements.
Tracking with Different Object Representations
While most objects in an autonomous driving scene can be represented as boxes, certain objects have irregular shapes, and are better described using polygons. In that case, those objects are hard to be parameterized in traditional tracking methods. Through a data-driven approach, our unified tracking model is able to process polygons just like regular boxes, making our AV system safer and more reliable.
Learning-based Track Management
Track management involves the process of controlling the life cycles for each track. The module will birth a track when it receives enough positive signals from a track’s measurements; and will kill a track when it stops receiving positive signals for a certain time. Traditionally, this process is achieved through heuristics. In the unified tracker model, we use the ML-based approach, and have a dedicated network output for making track management decisions. Our track management system has the following advantages:
- Occlusion Reasoning. One of the most important factors in track management is occlusion, where occluded tracks normally have weaker signals, and require more time for “coasting” (i.e. extending their life cycle). The unified tracker model is able to learn track-to-track occlusion through its transformer-based backbone, thus making better track management decisions.
- Context Aware. Thanks to the multi-task learning nature, the model has rich intermediate representations of the context features of each track, which can be further utilized for track management.
- Data Driven. Track management is a complicated process in that it is heavily dependent on scenarios. There are so many factors that could affect this process which are hard or even impossible to enumerate. A learning-based approach utilizes the power of data, making the system more adapted to the complicated world of autonomous driving.
Track Attributes Prediction
With a flexible network architecture, it is easy to include additional track attributes (for example, track visibility) as network output. Due to the feature sharing nature of the unified model architecture, it is easy to predict additional track attributes without affecting much of the model backbone.
With the fast-paced development cycle at Motional, this flexibility of introducing new attributes is crucial, as we constantly encounter and resolve new challenges in autonomous driving.
Unified ML Tracker
The multi-object tracking module in an AV system is responsible for processing various information across a period of time, grouping them into tracks, and providing motion estimations for each track. At Motional, we design a unified tracker model to include all those components, which is flexible enough to introduce additional features such as track management and attribute prediction. This fully data-driven tracking model is also one step closer to our future of an end-to-end ML autonomy system.
Interested in contributing to Motional's end-to-end ML architecture? We're hiring across engineering functions. Visit Motional.com/careers to apply.

