Read the first article in this series: Accelerating the human-in-the-loop data engine with visual web apps.
Offloading the Heavy Lifting — Web Workers and Shared Memory
The state management model ensures a responsive UI, but what about the raw computation? Operations like parsing a massive 3D point cloud, projecting it into a 2D view, or running complex geometry calculations can easily block the browser's main thread for hundreds of milliseconds, leading to a frozen, janky user experience.
The Problem: How do you perform heavy, synchronous computations without destroying UI fluidity?
Our Solution: A robust implementation of Web Workers and WebGL/WebGPU for parallel processing, coupled with SharedArrayBuffer for zero-copy data transfer.
- Web Workers: Allows the web application to use additional CPU processing threads so the user interface remains responsive when the application performs heavy workloads
- WebGL/WebGPU: Allows the web application to leverage the user’s GPU for graphically intensive visual application features and to leverage the GPU for special, highly parallel computational workloads
- SharedBufferArray: Allows the primary CPU thread to pass direct references to visual data (like Lidar Point Cloud Data) directly to Web Worker threads and WebGPU calls, eliminating the overhead of copying data between computational threads
We architected a system where the main thread's only job is to orchestrate work and update the UI. All heavy lifting is delegated to a pool of background worker threads.
The Geometry Worker Architecture
Our architecture includes a dedicated geometry worker thread pool, a long-lived background worker pool whose sole responsibility is to handle complex geometric and data-processing tasks.
Caching and Data Sources
To further optimize this process, our workers don't just perform computations; they also interact with a sophisticated data source layer. This layer interfaces with our backend APIs and maintains a client-side cache.
When a worker needs a piece of data, it first checks the local cache. If the data is present, it can be used immediately, avoiding a redundant network request. This caching is essential for providing a snappy experience when users are scrubbing through time sequences or switching between different sensor views.
The Result: A Truly Parallel Application
By rigorously offloading computation to Web Workers and using shared memory to eliminate data transfer bottlenecks, we have effectively created a multi-threaded web application.
- The Main Thread acts as a lightweight controller, focused on user interaction and rendering.
- The Geometry Worker Thread(s) act as a powerful, parallel processing engine.
This separation of concerns is fundamental to our ability to deliver a fluid, desktop-class experience in the browser while working with datasets that were once the exclusive domain of native applications.
The Workforce Task Management System: The Logic of Quality at Scale
A high-performance UI is only half the story. To be a true data engine, our platform must manage the lifecycle of millions of annotation tasks across a distributed workforce, ensuring every label meets our exacting quality standards. This requires more than just a slick interface; it requires a robust, auditable, and scalable system for managing the work itself.
This is the logic layer that sits between our users and our database, and it's built on a foundation of clear data contracts and a formal state machine.
From Raw Data to a Unit of Work
First, we must define what a "task" is. In our ecosystem, a task is not merely an image or a video clip. As our data model shows, a task is a rich context object, bundling raw sensor data with specific time samples, map data, and the labeling requirements for a given workflow. This ensures our annotators have all the information they need to produce high-quality labels.
The Task Management Service: A Clean Gateway
With a clear unit of work, we needed a clean, reliable way for the front-end application to interact with it. Instead of allowing UI components to make direct, ad-hoc calls to our backend, we centralized all interactions through a dedicated Task Management Service.
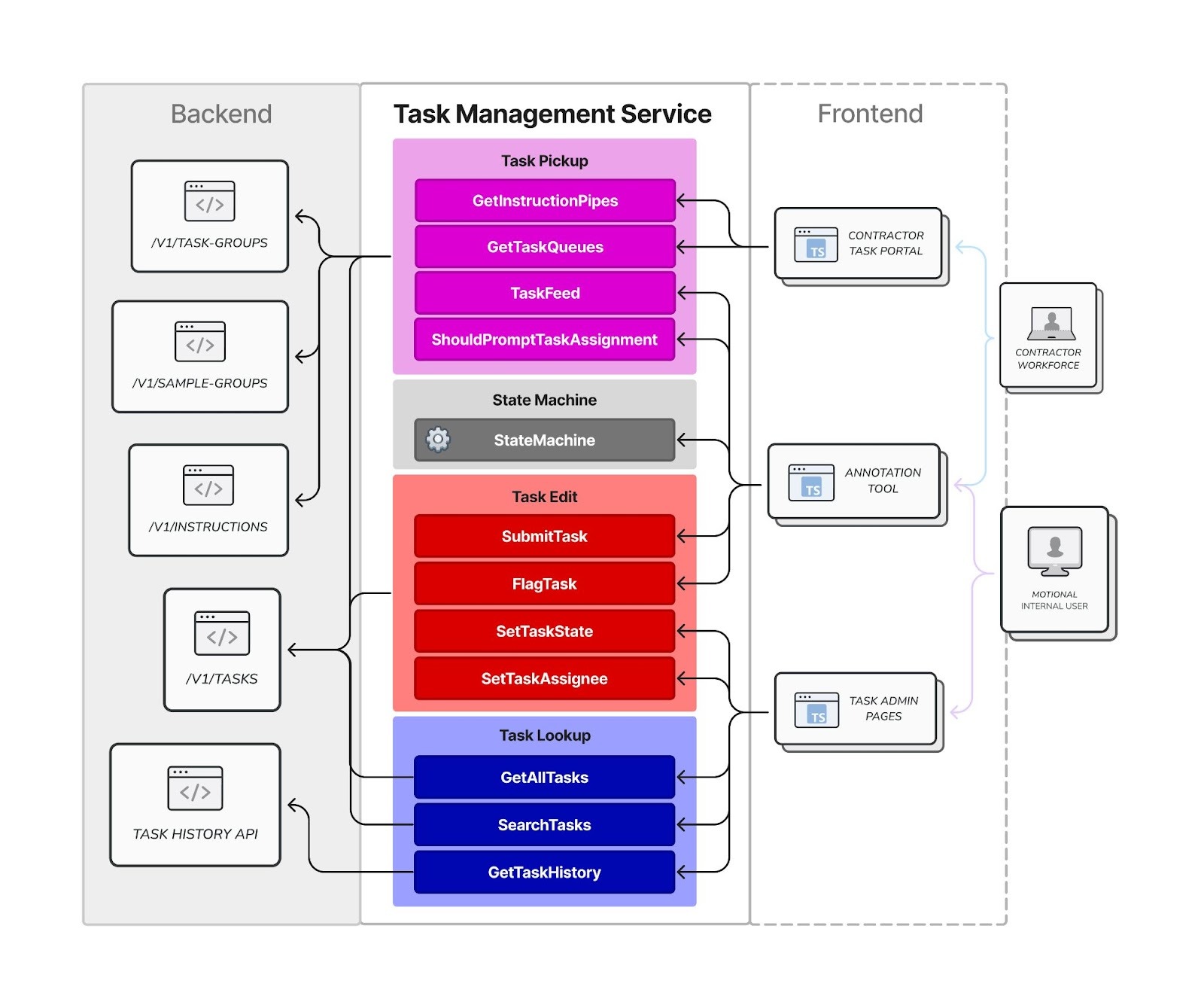 This service acts as a clean API facade within our front-end codebase. It provides logical, well-defined functions like GetTaskQueues, AssignTask, and SubmitTask. This architectural choice has two major benefits:
This service acts as a clean API facade within our front-end codebase. It provides logical, well-defined functions like GetTaskQueues, AssignTask, and SubmitTask. This architectural choice has two major benefits:
- Simplicity: Our UI components can focus on what they do best—displaying data and capturing user input. They don't need to know the messy details of API endpoints or request/response formats.
- Maintainability: All task-related logic is in one place. If an API contract changes, we only need to update the service, not dozens of individual components.
The State Machine: Enforcing the Rules of the Road
This is the heart of our quality system. The lifecycle of an annotation task is complex; it involves initial labeling, a QA pass, potential audits, and paths for flagging errors or reopening work. Managing this with simple boolean flags (is_approved, has_error) would quickly become an unmaintainable mess.
Our solution is to codify the entire business process into a formal Annotation State Machine.
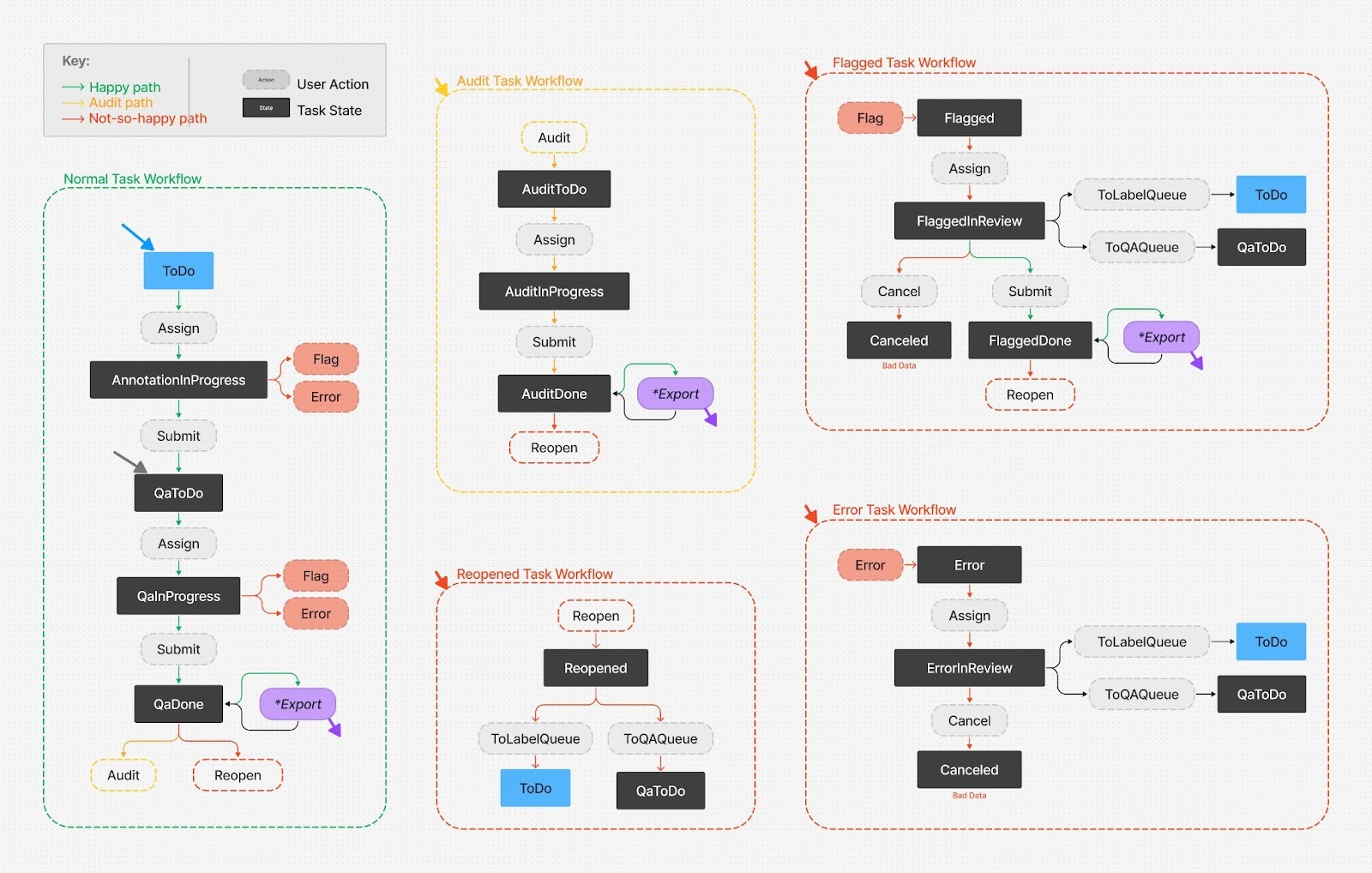
This state machine is not just a diagram; it's a declarative object in our codebase that defines every possible state a task can be in and, crucially, the only valid actions that can transition it from one state to the next.
This approach gives us tremendous benefits:
- Robustness: It is programmatically impossible for a task to enter an invalid state. The code enforces the business logic.
- Clarity: The entire lifecycle is documented in one place, making it easy for any engineer to understand the flow.
- Auditability: Every state transition is a well-defined event, which is invaluable for tracking the history of a task and debugging issues.
By defining the unit of work, providing a clean service to interact with it, and enforcing its lifecycle with a rigorous state machine, we can manage annotation at a massive scale while ensuring the highest levels of data quality and consistency.
Purpose-Built Architecture for a World-Class Tool
By investing in a scalable shell, a high-performance state engine, a maintainable codebase, and workforce management we've created a platform that not only meets the demanding needs of our ML teams, but is also ready to evolve for future needs.

