Polar Stream: Simultaneous Object Detection and Semantic Segmentation Algorithm for Streaming Lidar
This article was originally published on Motional's Medium page, Minds of Motional, on March 31, 2022
Lidar is one of the key sensors that autonomous vehicles (AVs) use to “see” objects in their environment, such as other vehicles, pedestrians, cyclists, or road obstacles. For a vehicle to understand what’s around it, accurately predict future movements, and safely navigate complex traffic scenarios, the inputs from the lidar must be timely and accurate. Other hardware, including radars, cameras, and microphones, also give AVs a complete understanding of their surroundings.
The traditional approach to lidar-based object detection has helped AV stacks mature to the point where AVs are currently operating safely on public roads. However, Motional’s research has unlocked an approach to streaming object detection that reduces latency while increasing accuracy, giving AVs even better data needed to make safe decisions.
Streaming Lidar Object Detection vs Traditional (full-sweep) Lidar Object Detection
As the lidar rotates, it generates data that is streamed sequentially and incrementally in the form of wedge-shaped pointcloud sectors. As soon as each sector arrives in the onboard perception system, streaming object detection algorithms process the data and detect objects within the field of view of each sector.
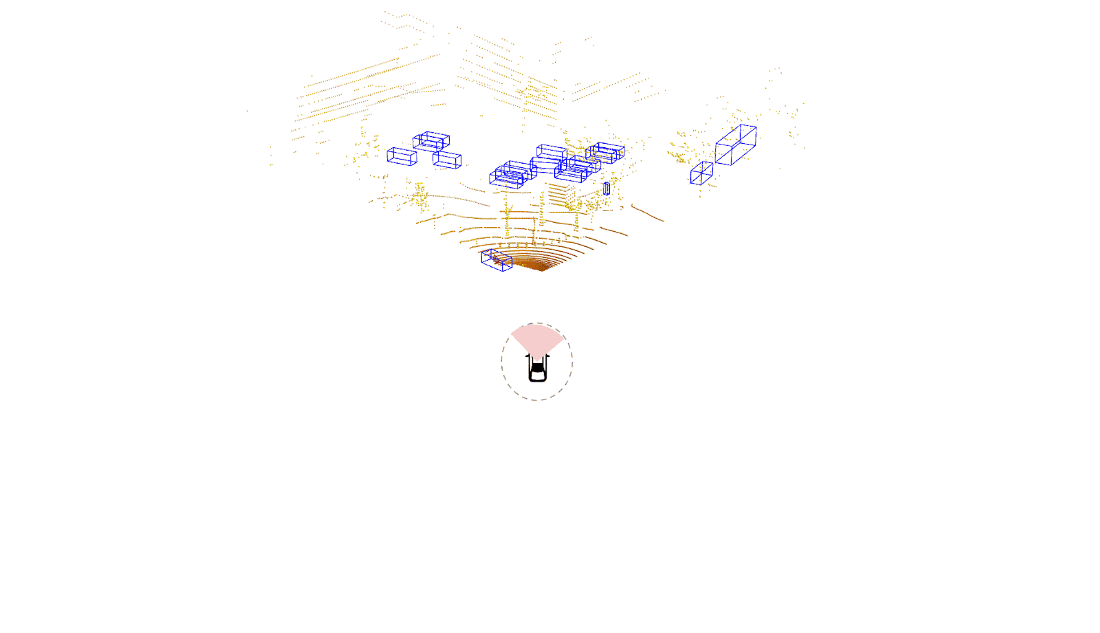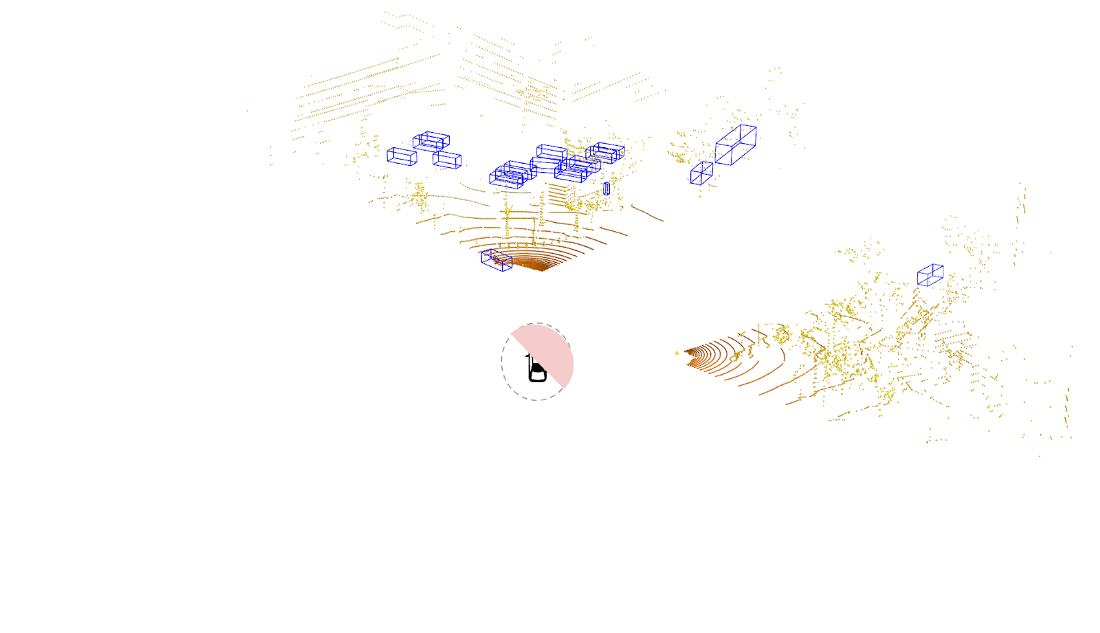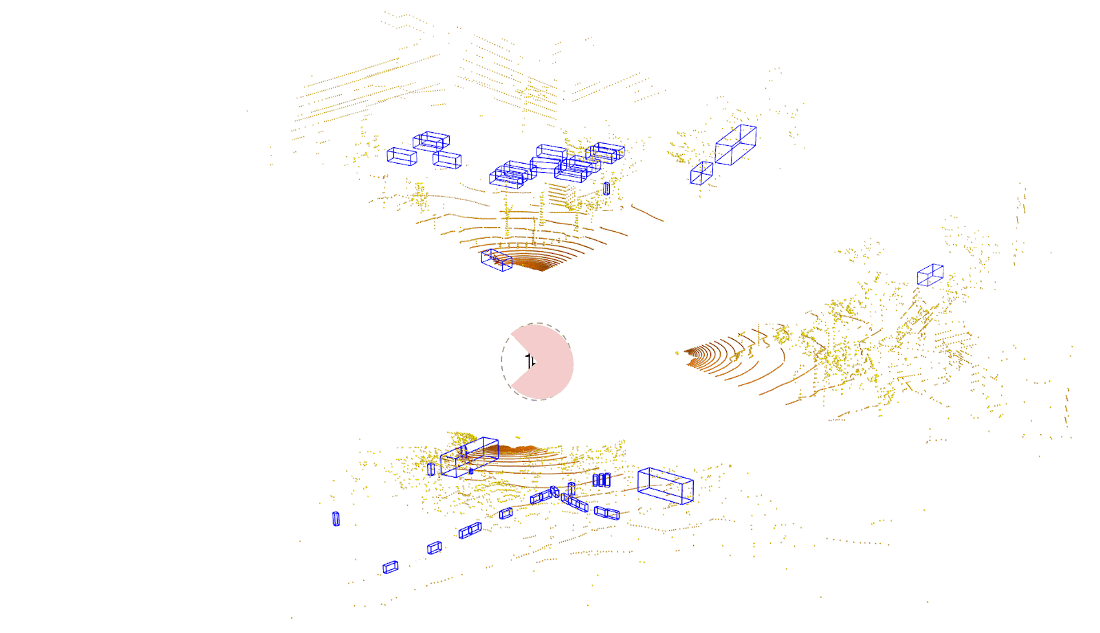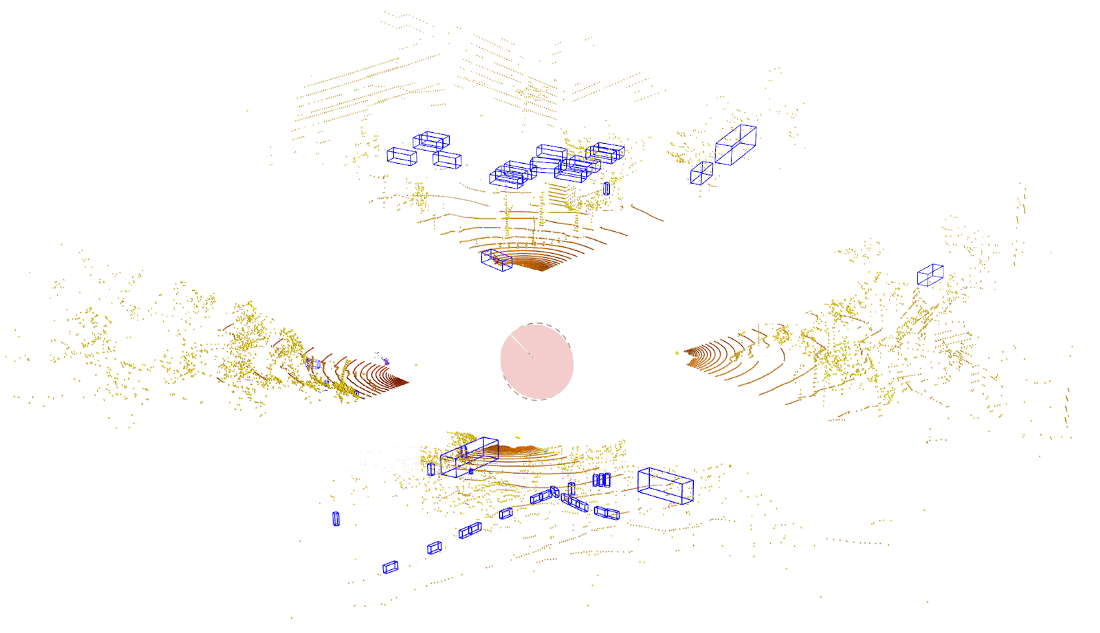
An example of a traditional lidar object detection algorithm is shown on the left in the figure below. Here, we wait for the lidar sensor to finish a complete scan. The data is then processed using a powerful onboard compute to detect objects all around the ego vehicle in a single snapshot. This approach introduces latency due to both the time needed to capture the data (represented by the pink part of the bottom plot) as well as time to process the data (shown by the gray part of the bottom plot).
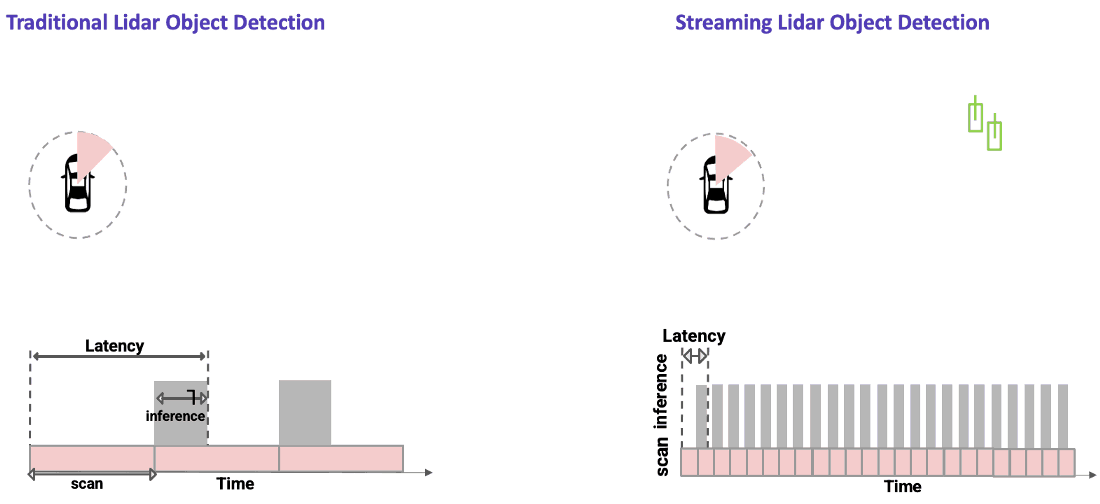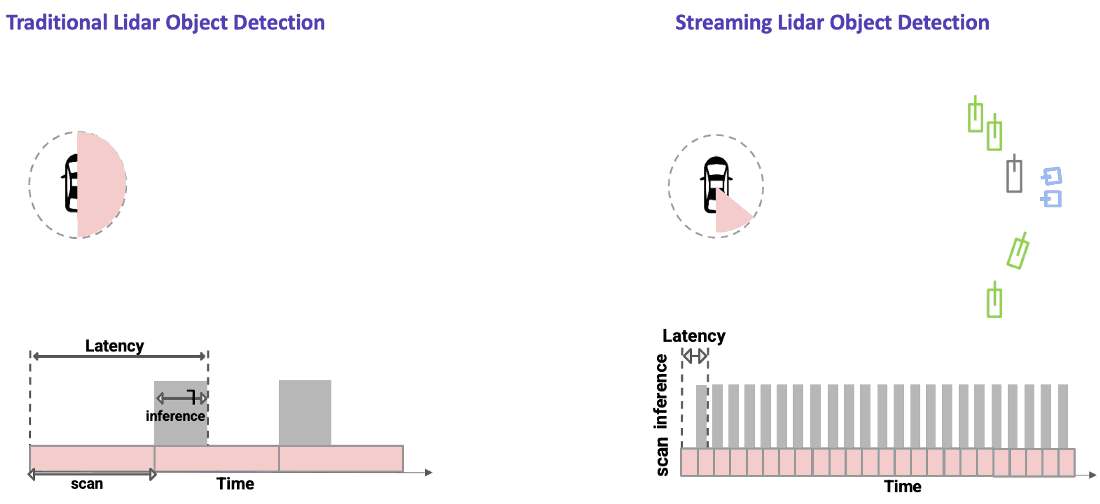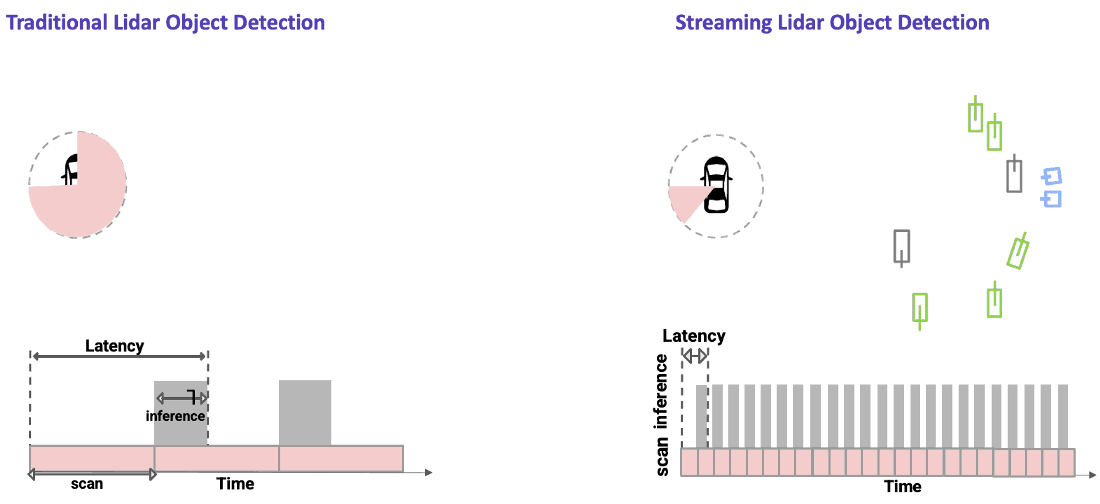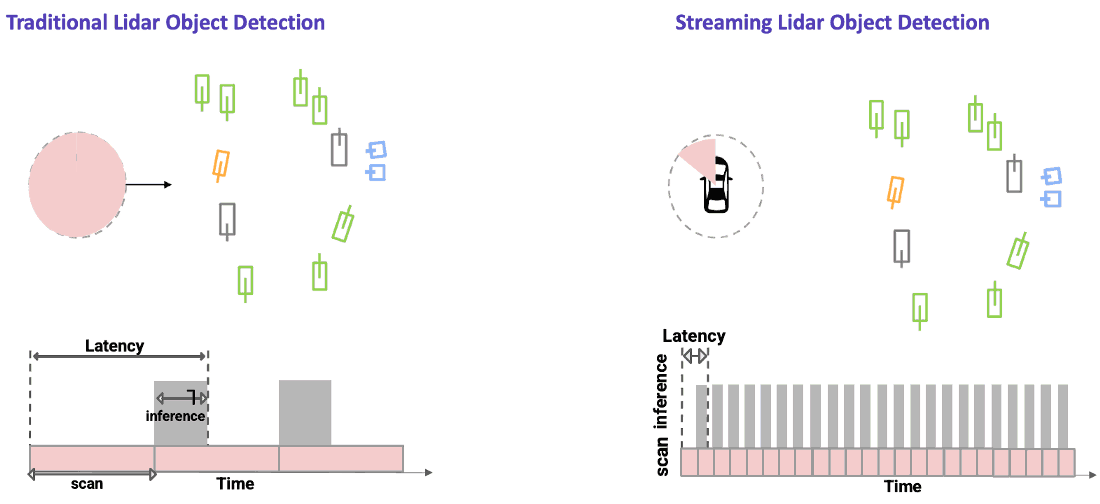
In streaming lidar object detection, the detection algorithm doesn’t wait for the entire scan to finish; instead it processes lidar data as soon as it arrives, as clearly seen in the animation above on the right. As the lidar is rotating, we are detecting objects incrementally in those wedge shaped regions without waiting for the entire scan to complete. This substantially reduces the end-to-end latency.
Why is streaming perception important?
By minimizing end-to-end latency, the current state of the driving environment is more accurate. When we detect an object using the non-streaming object detection approach, we are detecting the past position of that object. During the time it takes for the lidar to finish its scan, fast-moving objects have already moved to a different location. For AVs, those milliseconds could make a difference in detecting when a vehicle is changing lanes or stopping short.
The image below demonstrates this clearly. It shows that the lidar is operating at 10 Hz and the packets are captured every 10 ms. For a traditional system, it takes 100 ms for the lidar scan to complete, meaning the detection (as shown by the red box) is already outdated as the agent has moved to a new position. In a streaming-based approach, we detect the object more accurately as soon as the second packet is captured after 20 ms.
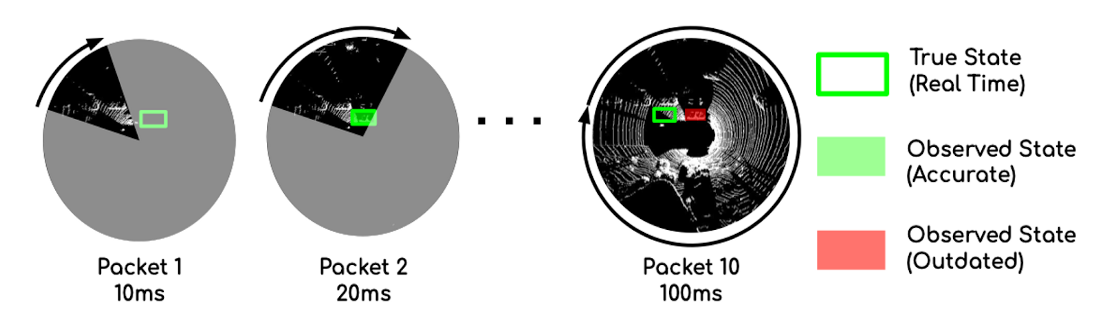
Source: Frossard, Davi, et al. “StrObe: Streaming Object Detection from LiDAR Packets.” (2020).
Challenges associated with Streaming Lidar Perception
Streaming lidar perception comes with several challenges. The first challenge is the inefficient input representation.
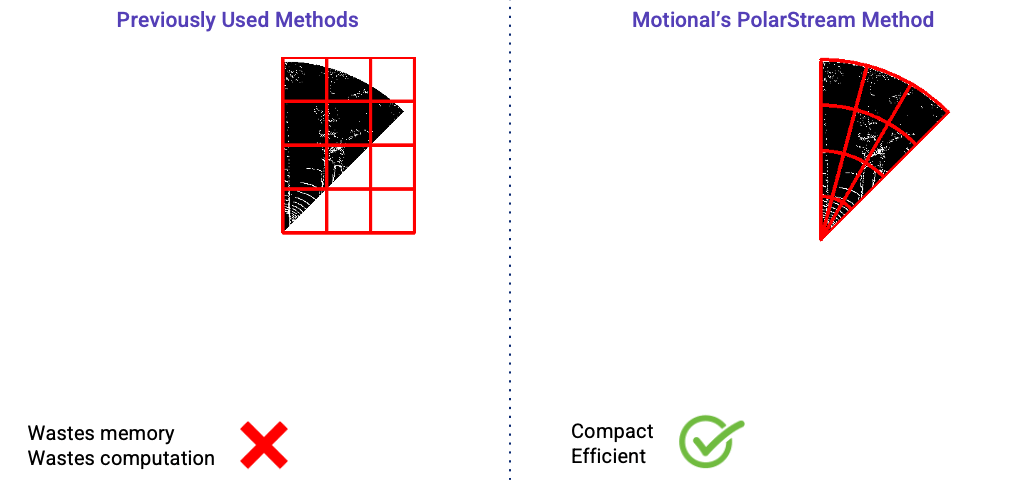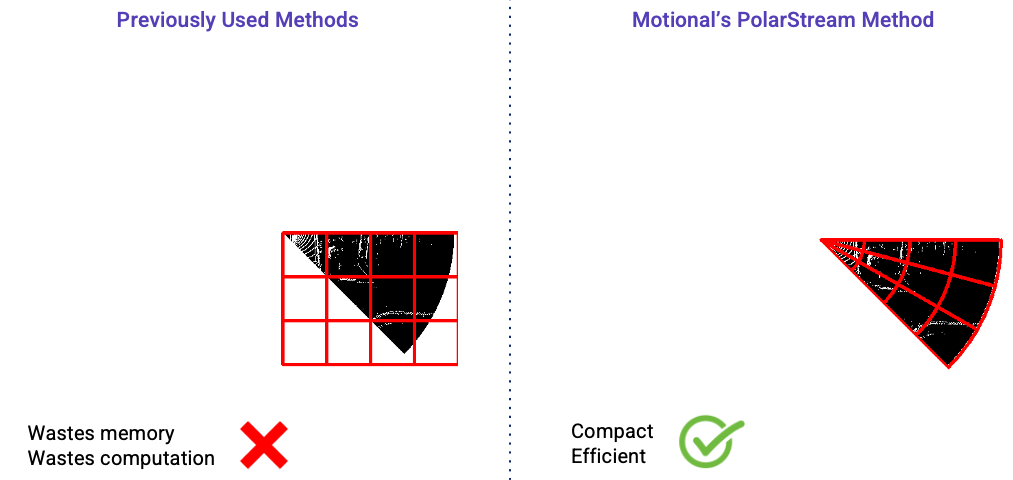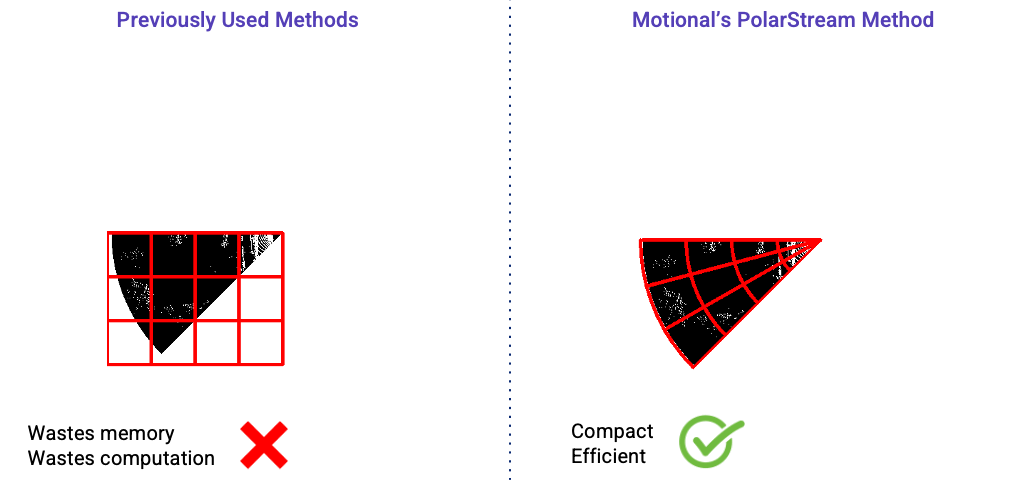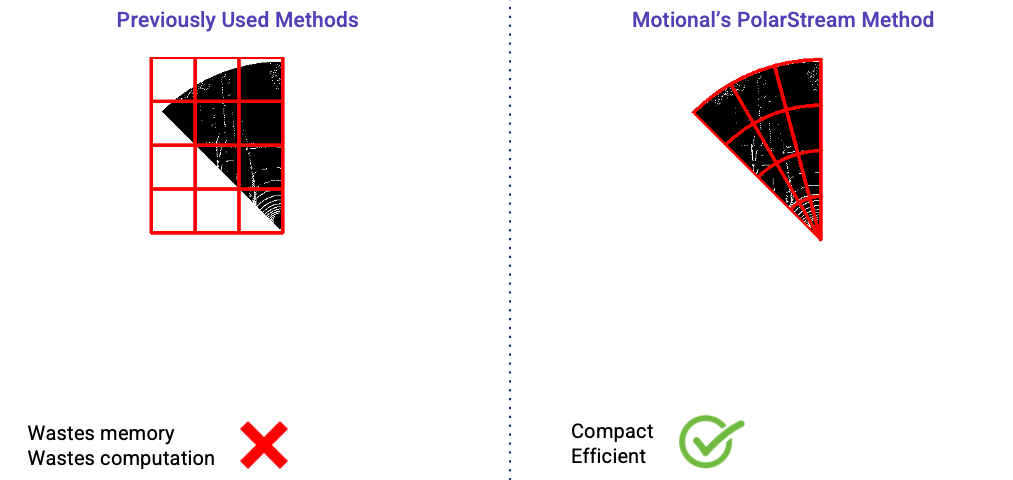
The actual input region for each streaming lidar sector is wedge-shaped, like a slice of pizza, as shown in the gray area in the figure below. However, most efficient lidar object detectors are convolutional neural networks operating on the bird’s-eye view and these networks are more efficient to operate on rectangular inputs. So even if the input pointcloud is wedge shaped, we will need to encode them as rectangular regions (as shown by the red box below) if we are using a cartesian coordinate system. Using a rectangular region, however, can be problematic.

First, it requires extra work to hand-design the input rectangles because the size of the rectangle changes for different sectors. Second, it wastes at least half of the rectangle because the wedge-shaped input region only fills a portion of the rectangle. The remaining sections of the rectangle are empty.
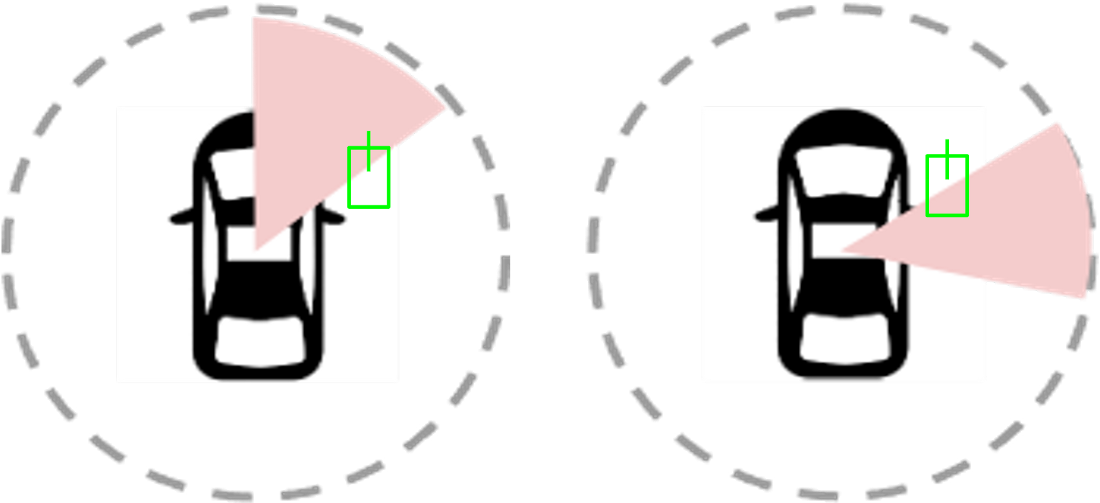
The second challenge for streaming object detection is the limited spatial view of each lidar sector. In the figure below, an object shown in the green box may not be fully captured within one sector. Detecting such an object from its partial observation is difficult. As a result, the onboard perception system may not accurately detect objects at the sector boundaries.
PolarStream Overview
In this section, we introduce PolarStream, our state-of-the-art, streaming lidar-based perception model and mainly talk about our two contributions to solve the challenges associated with streaming lidar perception: a) Use of the Polar coordinate system and b) Multi-scale Context Padding.
Polar Representation
Previous streaming lidar object detection approaches [2][3] both used cartesian coordinate systems to encode the lidar pointclouds. Thus, a rectangular input region was fed to the model which is wasteful both in terms of memory and computation. In contrast, we have explored using polar representation and wedge-shape grids to encode the input point cloud. It is more compact and efficient than the previous streaming approaches as shown in the figure below.
Multi-Scale Context Padding
Previous methods use an additional memory module to aggregate information from all the sectors. The motivation behind using the memory module is that features from the neighboring sectors will help improve detection performance, especially for objects living on sector boundaries.
Our PolarStream model , in contrast, does not require any extra memory module while still being able to encode features from the neighboring sectors in an efficient manner. We do so by using two multi-scale context padding approaches described below: Trailing-Edge Padding and Bidirectional Padding.
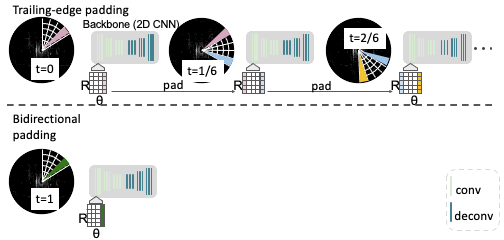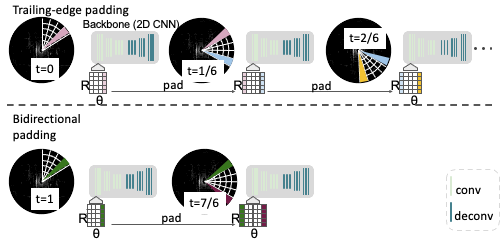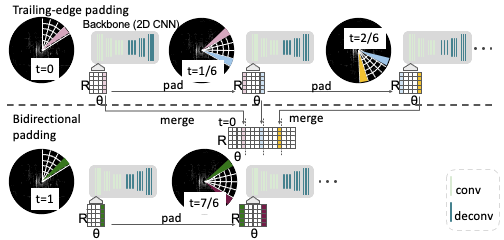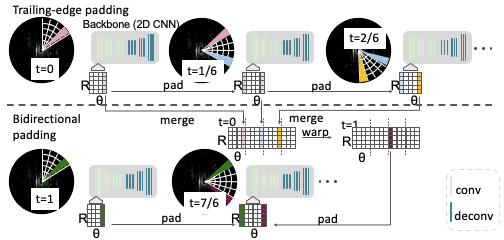
Trailing-Edge Padding

We found by virtue of using the polar coordinate system, when we unfold the input sector to a rectangular feature map along the range and azimuth dimensions, i.e. the r and theta dimensions, the neighboring sectors spatially connect. We take advantage of this spatial connectivity and simply pad the trailing edge of the current sector with the previous sector. This is shown in the diagram above where the sector being processed at time t=⅙ is being padded on it’s trailing edge by the pink wedge coming from the previous sector at time t=0. We call padding from the previous sector “trailing-edge padding.” And we repeat trailing-edge padding until one full scan is completed.
Further, we do trailing-edge padding at the feature map level instead of simply padding the points from the previous sector and making the current sector bigger and inefficient to process. We do feature map padding by simply replacing zero-padding, a commonly used operation before convolutions, with the features from the previous sectors. And we do so across different strides of the backbone, allowing us to efficiently enhance the receptive field of the current sector.
The advantage of our trailing-edge padding approach is that we introduce no extra modules and thus no extra latency or computation.
Bidirectional Padding
While we know it’s possible to pad from the previous sector; the question is whether it’s also possible to pad from future sectors?
The answer is “no,” but there is a workaround. We can not access the future sectors without waiting for them to arrive, thereby increasing the latency of our model. But we can certainly approximate the future sectors. We do so by utilizing different time frames. We merge full-sweep maps from the past time frame and warp it to the current time frame by performing ego motion compensation. In addition to trailing-edge padding, we then pad these approximated features of the future sector coming from the past frame. We call this bidirectional padding. It allows us to see a more complete picture using both the preceding and the following sectors.
Comparison with Previous Streaming Methods
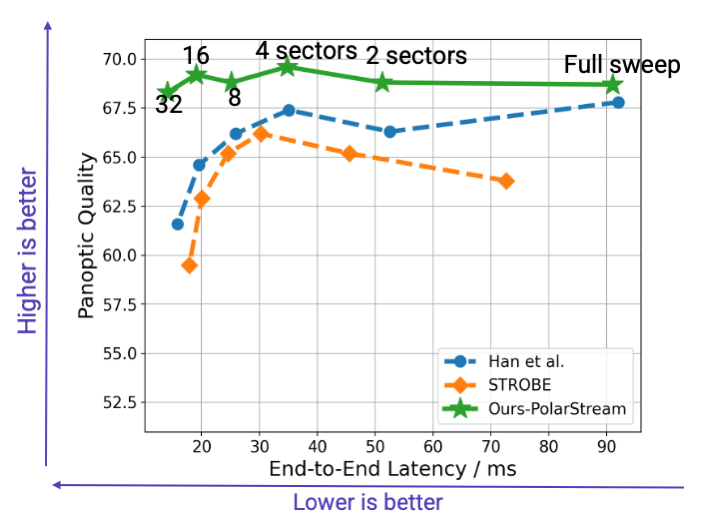
The graph above shows the comparison of our PolarStream model against two previous state-of-the-art approaches [2][3] on the nuScenes [4] validation set. The horizontal axis is the end-to-end latency, meaning lower is better. The vertical axis is panoptic quality. It is a metric for perception performance, meaning the higher the better. We show the comparison when the full-sweep point cloud was split into 1, 2, 4, 8, 16 and 32 sectors.
The results show that PolarStream is not only more accurate, but also faster than previous methods. It’s interesting to notice that as the number of sectors increase, each sector becomes smaller so the challenge associated with limited spatial view becomes more severe. Detecting from smaller sectors becomes more and more challenging for previous methods (shown in blue and orange), you see a clear trend that the accuracy drops. But PolarStream maintains almost the same or even better accuracy for smaller sectors. This is surprising because the community used to believe that streaming improves the speed by compromising on the accuracy. But we are showing for the first time that streaming based perception approaches can be both faster and more accurate.
Comparison with SOTA Full-sweep Methods
While all the results in the last section were presented using the fast encoder and backbone from [5], we also compare PolarStream’s full-sweep model against the current state-of-the-art, lidar-only, 3D object detection and semantic segmentation algorithms on the nuScenes™ leaderboard. They both use the slower but more accurate VoxelNet encoder and backbone from [6].
As shown in the tables below, PolarStream is indeed competitive with the current SOTA lidar-only 3D object detection and semantic segmentation approaches.

CONCLUSION
Streaming-based perception approaches have the potential to dramatically reduce the end-to-end latency of the perception systems on AVs. This reduced latency means faster reaction by the ego vehicle to fast-moving agents around it, which in turn means safer and smoother rides. PolarStream, the new streaming lidar object detection and semantic segmentation model, is not only more accurate as compared to previous streaming perception approaches, but also a lot faster.
At Motional, we have always had a strong commitment to open-source as is evidenced by our various open-source datasets (nuScenes™, nuPlan™, nuImages™, nuReality™) and publications. We continue the trend and release the codebase for PolarStream here. This repository is not only the official implementation of PolarStream [1] but also includes our reimplementation of [2] and [3]. We hope that our codebase encourages further research on this important topic.
References
[1] Chen, Q., Vora, S. and Beijbom, O., 2021. PolarStream: Streaming Object Detection and Segmentation with Polar Pillars. Advances in Neural Information Processing Systems, 34.
[2] Han, Wei, et al. “Streaming object detection for 3-d point clouds.” European Conference on Computer Vision. Springer, Cham, 2020.
[3] Frossard, Davi, et al. “StrObe: Streaming Object Detection from LiDAR Packets.” arXiv preprint arXiv:2011.06425 (2020).
[4] Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh Vora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuScenes™: A multi-modal dataset for autonomous driving. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11621–11631, 2020.
[5] Lang, A.H., Vora, S., Caesar, H., Zhou, L., Yang, J., Beijbom, O.: Pointpillars: Fast encoders for object detection from point clouds. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 12697–12705 (2019)
[6] Y. Yan, Y. Mao, and B. Li. SECOND: Sparsely embedded convolutional detection. Sensors, 18(10), 2018.
[7] Yin, T., Zhou, X. and Krahenbuhl, P., 2021. Center-based 3d object detection and tracking. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 11784–11793).
[8] Zhou, H., Zhu, X., Song, X., Ma, Y., Wang, Z., Li, H. and Lin, D., 2020. Cylinder3d: An effective 3d framework for driving-scene lidar semantic segmentation. arXiv preprint arXiv:2008.01550.

