Motional plans to bring driverless technology to cities worldwide. In order to do so, we must scale our machine learning (ML) pipelines to handle larger datasets, train more complex models, evaluate more metrics, and simulate more scenes. Consequently, we have been reshaping a few key development phases to enhance scalability and enable continuous learning.
Background: (Off-Board) End-to-End ML Pipeline
This post primarily focuses on our off-board ML pipeline that runs on the cloud, before a model is deployed to an on-board environment. A typical pipeline includes the following phases:
- Drivelog Ingestion: Reload the drivelogs collected by multiple sensors from cars to cloud storage
- Human Labeling: Extracts certain scenes from drivelogs for annotation
- Drivelog Refinement: Refines the uploaded drivelogs and restructures the data for the more efficient access by the downstream
- Model Training:
- Training Data Preparation: In contrast to Step 3, where the refined drivelogs are mostly model-agnostic, this step can allow ML engineers to prepare the training input data customized for different models
- Training: Consumes the training input and outputs a model checkpoint
- Model Evaluation:
- Metric Computation: Runs batch inferences and computes evaluation metrics
- Visualization & Analysis: Visualizes the metrics in an UI and runs interactive analysis
- Resimulation & Regression Tests: In contrast to the model evaluation at Step 5, which only takes into account a single model at a time, this step plays back certain scenarios and runs regression tests that can involve multiple models

(Off-Board) E2E ML Pipeline
Now let’s dive into the design of scaling three key phases; training data preparation, metric computation, and training.
Scaling Training Data Preparation
The training data preparation can deploy a pub-sub architecture.
- At the upstream data publisher side, infrastructure teams fully own the release of each data source.
- At the downstream data subscriber side, each model has its own training data preparation phase, which can be decoupled from the upstream data publishers. Each model can subscribe to an arbitrary number of data sources and transform into the training input data. Training data preparation can be integrated with the feedback loop of training and evaluation, and ML engineers can easily make changes independent of the upstream data sources.
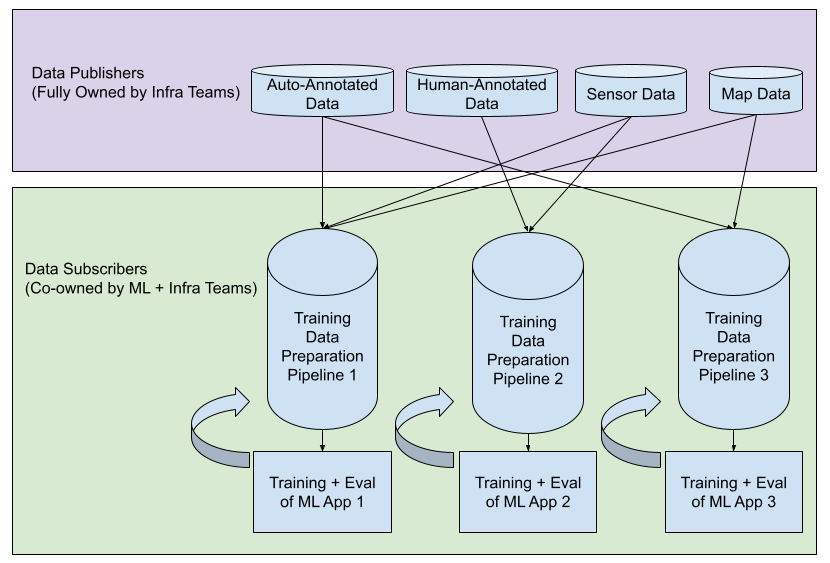
Pub-Sub Architecture of Training Data Preparation
Moreover, the system is built on top of Ray Data and can support the following features:
- Incremental Data Processing: Continuous learning is critical for our fast iterations. When a relatively small amount of the latest data is released, if we don’t need to refresh the old data, we should only need to process the new data. The outputs can be easily added as a part of training input without any data merge with the existing large datasets. Specifically, we choose Parquet as both the input and output formats, and stay away from any database snapshots that are non-trivial to merge or partition.
- Flexible Data Fixes/Optimizations: Besides fixing and optimizing the model architecture, ML engineers often need to fix and optimize the training data. That’s why we need to offer great flexibility to make and test data-side code changes:
- The data pipeline is 100% Pythonic and expressed in high-level Ray Data API, which is easy for ML engineers to iterate over and there is no need to involve error-prone multiprocessing/multithreading.
- The data pipeline can be seamlessly incorporated into the subsequent training and evaluation as a single job for fast regression tests in terms of model quality.
- High Performance & Reliability:
- Horizontal scaling can be supported to process massive amounts of data efficiently. This is very similar to the traditional ETL (Extract, Transform, and Load) workloads needed at the upstream data publisher side.
- Unlike the traditional ETL implemented on Spark, here we can avoid introducing any dependency on JVM (Java Virtual Machine), which not only incurs the overheads of transferring data from the JVM to the Python process, but also complicates the maintenance of our Python-centric ML codebase.
- Ray Data library provides built-in fault tolerance. This is critical for handling occasional OOMs.
- Heterogeneous Computing: Although most data processing workloads are executed on CPU, we might also need to run some workloads on GPU. For instance, we might want to generate some synthetic data and augment our training datasets by running the inference of a certain diffusion model on GPU.
Scaling Metric Computation
We designed a high-performance and flexible metric computation framework on top of Ray Data to address some unique challenges. Unlike many natural language models or ads ranking models, which mainly need to compute a very small number of high-level aggregate metrics like perplexity and entropy, our models need to be evaluated by hundreds of metrics over a large number of (edge) cases to meet our safety requirements. The design considerations are as follows:
- Dataframe-Like Ray Dataset as the First-Class Citizen: It turns out that our ML engineers are often much more comfortable with a tabular view than a tensor view (e.g., offered by TorchMetrics) when implementing an evaluation logic. Particularly, one main consideration is the support for grouping operations – some metrics might need to be grouped as an 1D histogram or a 2D headmap.
- High Composability: Some metrics can often have dependencies on some other metrics. Without such a framework, multiple metrics often have to be computed together in the user code, resulting in a very tight coupling and high maintenance cost. In our framework, each metric can be expressed as a standalone class with embedded dependency information. Thus, a very simplified user interface can be provided:
- The user only needs to specify what metrics to compute, and the system is able to decide which metric to compute first based on the dependencies.
- Each metric computation can be viewed as a plugin, so it is fairly easy to add new metrics.
- High Performance & Reliability:
- Besides the same high performance and reliability properties mentioned in the design of Training Data Preparation, the framework can also support vectorization via map_batches API. This is important for performance because many operations in the evaluation code can be vectorized.
- By analyzing the metric dependencies, the framework can automatically reuse any intermediate results to avoid recomputation. For example, the result of a confusion matrix can be reused for computing many other metrics like precision/recall, F1, etc.
- Heterogeneous Computing: The motivation is similar to the aforementioned training data preparation. It can be much faster to compute some metrics like IoU (Intersection Over Union) and convex hull on GPU.
Scaling Training With ML-Based Online Data Selection
If we directly take all the available training input data into our model trainer, the input will be dominated by uneventful driving behaviors where the vehicle keeps the same lane and speed. Thus, careful data selection is critical for the model to learn the capabilities that can only be captured by the minor scenarios such as lane changes, left and right turns, passing an inactive vehicle, and other vehicle maneuvers.

Workflow of Heuristic-Based Offline Data Curation
As a starting point, let’s first see a typical workflow of heuristic-based offline data curation:
- Unwanted data can be removed from the pre-selected data by a data linter, which consists of a set of filters.
- A number of datasets are curated by different data mining heuristics, where each dataset corresponds to a certain scenario.
- These datasets are resampled based on the weights carefully tuned by the user, and then combined into a single mixed dataset.
There are a few limitations of this approach:
- The filters in Step 1, data mining logics in Step 2, and weighting in Step 3, are all essentially heuristics handcrafted by domain knowledge. This process is hard to maintain and scale when more autonomous vehicle (AV) capabilities need to be unlocked.
- There can be a disconnection between the heuristics deployed in data curation and the final goal we want to optimize for in the later model training phase. It can be very difficult to validate whether some heuristics are really effective for the model to learn a certain capability and not cause other potential regressions.

Workflow of ML-Based Online Data Curation
We believe that the next-generation data curation process should be ML-driven. The results of training and evaluation should guide the data selection, and this can also significantly improve the maintainability by eliminating the convoluted heuristics. More specifically, we can seamlessly incorporate online data selection into elastic training, by training over a “dynamic” dataset selected based on the latest model checkpoint. The key idea is to always trainon the most worth-learning data with regard to the current model checkpoint, with the following steps as an example:
- The pre-selected data can be created by some simple queries.
- By leveraging a certain online data selection algorithm, we can create a data subset. For instance, the selected dataset can have the top 10% highest RHO (Reducible Holdout) Loss, which is expected to be:
- Low-noise: no complex data linting needed;
- Task-relevant: no complex data mining needed;
- Non-redundant: no need to deduplicate datasets;
- Worth-learning: no need to resample datasets.
- The model is trained on the curated data for 1 epoch and then a model checkpoint is produced.
- With the latest checkpoint, two asynchronous jobs can be executed concurrently:
- Validation during training;
- Data selection to produce another curated dataset for the next epoch. This dataset will be different from the last curated dataset because the training loss will be refreshed by the latest model checkpoint.
Compared with a typical online data selection process that is carried out during data loading, where the top percentage of data is selected from super batches, our design can have a few advantages:
- The curated dataset represents the global top percentage of the entire dataset, instead of the top percentage of each super batch. The difference is comparable to the global maximums against the union of local maximums. Given that sometimes the size of a super batch can be relatively small due to memory constraints (recall that this is also why group normalization was proposed in vision tasks to replace batch normalization), global maximums might be able to lead to a higher model quality.
- Data selection can overlap with the validation process for faster training.
- Since the parallelism size of data selection does not need to be restricted to the number of data loader workers, a much larger number of data selection workers can be used.
Particularly, 2) and 3) require elastic training that can provide dedicated resources for data selection.
Motional is reshaping its end-to-end ML pipelines to meet the scaling demands of a global driverless deployment. We have demonstrated three example design cases, including 1) a pub-sub architecture deployed by training data preparation for continuous learning, 2) a flexible and high-performance metric computation framework for efficient model evaluation, and 3) an elastic training design that can seamlessly incorporate ML-based online data curation. These innovations aim to improve system scalability and accelerate the model development velocity.

