The future of autonomous vehicles (AVs) lies in scalability, adaptability, and human-like driving behavior. At Motional, we are pioneering the next evolution of AV technology by transitioning from traditional rule-based planning systems to an end-to-end machine learning (ML) powered motion planning system. This shift allows us to address some of the key limitations of legacy AV architectures and embrace a future where AVs rapidly learn, adapt, and improve with every mile driven.
Traditional AV stacks follow a sequential modular pipeline: Sensors -> Perception → Tracking → Prediction → Rule-based Planning. While this approach offers modularity, interpretability and structured debugging, it also introduces significant drawbacks:
- Information Loss: Each module only passes selected information, defined by engineers, to the next, discarding potentially valuable context that could improve decision-making.
- Error Accumulation: Small inaccuracies in perception propagate through prediction and into planning, compounding errors.
- Scalability Bottlenecks: Rule-based planning systems become increasingly brittle as complexity grows, making them difficult to extend to new Operational Design Domains (ODDs). Furthermore, as rules conflict and interact in unforeseen ways, debugging becomes increasingly difficult, impeding real-world deployment at scale.
- Limited Adaptability: Human drivers rely on intuitive, experience-driven decision-making, something rule-based systems struggle to emulate.
By embracing an ML-first approach, Motional is building the foundation for the future: a fully end-to-end ML-based AV system. In this blog post, we will introduce our initial steps in this direction—developing an ML-powered Motion Planning system that integrates prediction and planning into a unified framework.
ML-Powered Motion Planning: Towards Human-Like AV Behavior
At the heart of Motional’s next-generation AV stack is an ML-based Motion Planner designed to mimic human-like driving behavior while maintaining safety and efficiency. Our approach is built on three core pillars:
- Scene Encoder - Generator - Ranker Architecture and Joint Prediction-Planning Task
- Closed-Loop Training and Reinforcement Learning for On-Road Adaptability
- Data Mining and Augmentation for Real-World Scalability
Scene Encoder - Generator - Ranker Architecture and Joint Prediction-Planning Task
Leveraging PredictNet for Smart Motion Planning
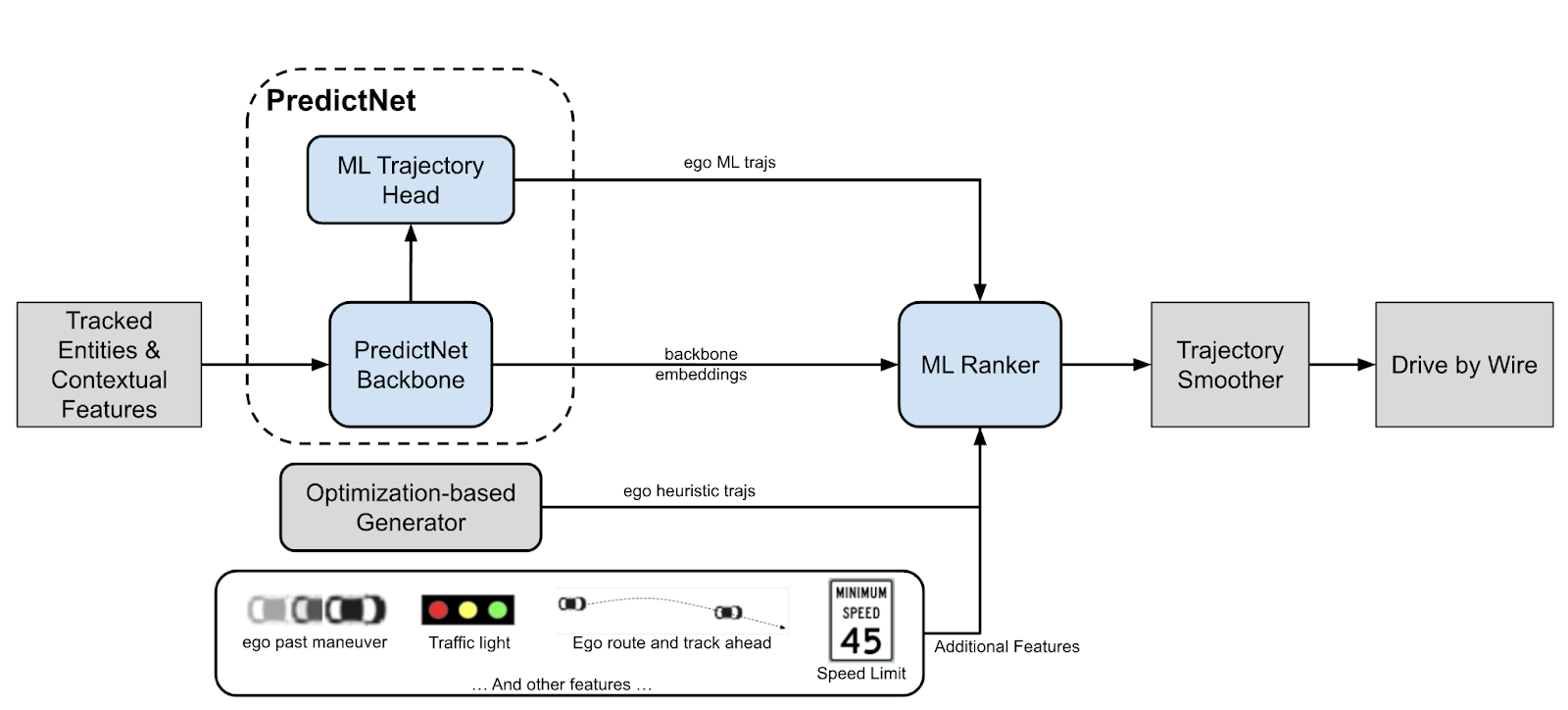
Our ML Planner leverages advancements in PredictNet, Motional’s advanced prediction model that encodes rich contextual information from the driving environment through learning from agent behaviors. Unlike traditional planning systems that explicitly define and optimize trajectory sets, we harness PredictNet’s learned embeddings to generate and rank future trajectories.
How it Works:
- PredictNet as a Scene Encoder: PredictNet learns spatiotemporal relationships between vehicles, pedestrians, and static map elements, encoding each scene’s semantic contexts into a structured, high-dimensional latent representation suitable for downstream planning.
- Transformer-Based Embeddings: PredictNet leverages a Transformer-based model to create embeddings that retain rich contextual information. These embeddings capture interactions between road agents and environments, allowing the model to reason about future behaviors and long-term dependencies for more informed and adaptive planning decisions.
- Trajectory Generation: We train PredictNet to propose a limited but highly-representative set of trajectories. These ML-generated trajectories are augmented by an optimization-based low-latency trajectory generator, providing a high-precision and rich set of motion plans that provide high coverage of possible ego-vehicle (the AV) maneuvers.
- ML Ranker for Optimal Decision Making: A ranking model evaluates these generated trajectories based on a multi-objective loss function incorporating safety, comfort, and human-likeness. The ranker model is trained to balance near-term reactiveness to immediate traffic conditions with long-term trajectory feasibility, ensuring that decisions are both adaptive and sustainable over the entire planning horizon.
This approach directly minimizes information loss between prediction and planning, addressing one of the fundamental challenges in traditional AV stacks.
Transformer-Based Model Backbone and Joint Prediction-Planning Training
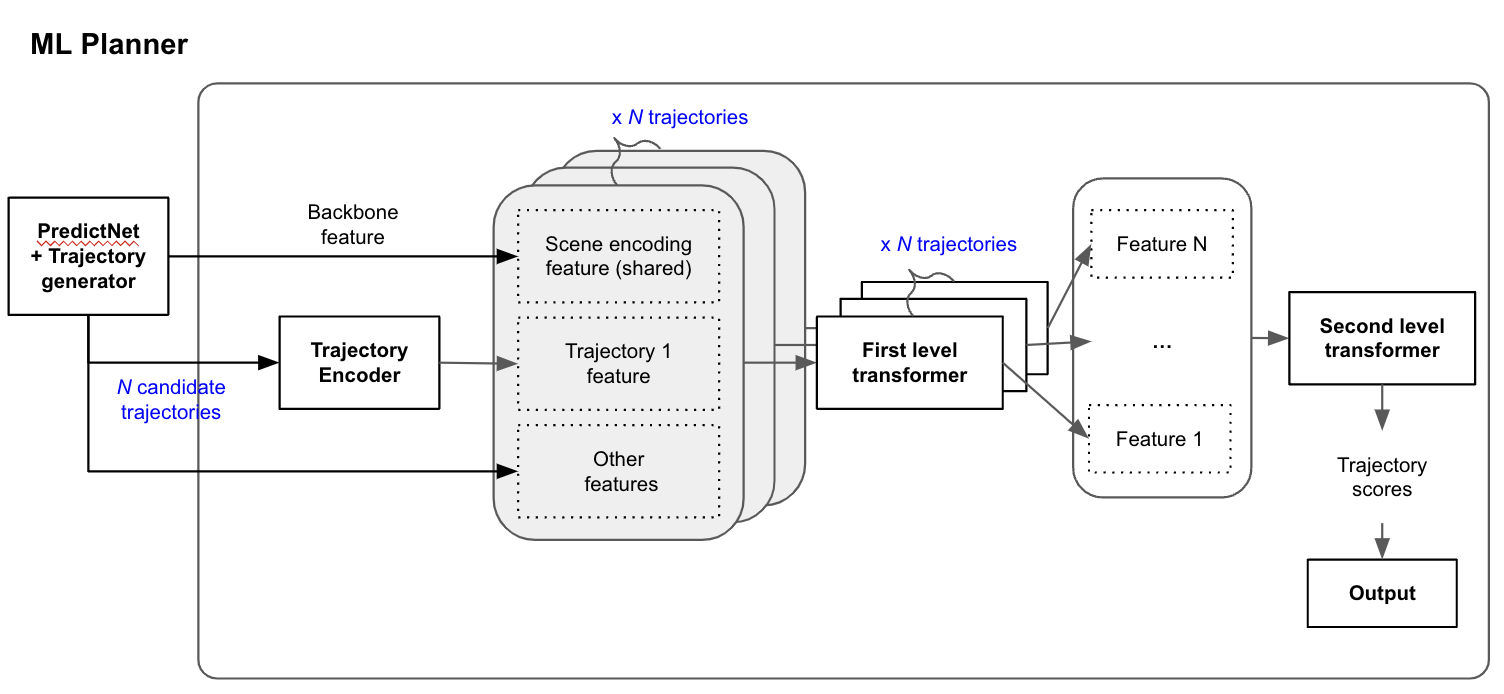
Transformer-based architectures have revolutionized natural language processing (NLP), computer vision and every aspect of AI. Motional is harnessing their power for scene encoding and joint task learning. Instead of treating prediction and planning as independent modules, our ML Planner shares a unified Transformer-based representation co-trained with PredictNet. This approach allows the system to learn complex interdependencies between agents, map elements and ego, minimizing information loss and enabling more cohesive decision-making across the AV stack.
How it works:
- Global Context Understanding: Self-attention mechanisms allow the model to encode relationships between agent-agent, agent-ego, and ego-environment interactions. By leveraging self-attention, the model can track multi-agent interactions over time, improving long-term decision-making for complex traffic scenarios.
- Robust Representation Learning: A shared Transformer backbone allows Prediction and Planning to co-learn meaningful scene and agent representations, reducing prediction-planning mismatches. Unlike rule-based approaches that rely on handcrafted heuristics, this data-driven learning approach enables greater generalization to unseen scenarios and environments.
- Joint Training for Bidirectional Learning: While we initially train prediction and planning tasks separately, we achieve even greater performance improvements through joint training, allowing bidirectional knowledge transfer. This co-training approach allows the planning model to adapt based on learned predictions and vice versa, allowing the AV to operate with greater foresight and adaptability.
This integrated approach brings us one step closer to a fully end-to-end ML AV stack that continuously refines its performance based on real-world driving data, ensuring scalable deployment across diverse driving environments.
Closed-Loop Training and Reinforcement Learning for On-Road Adaptability
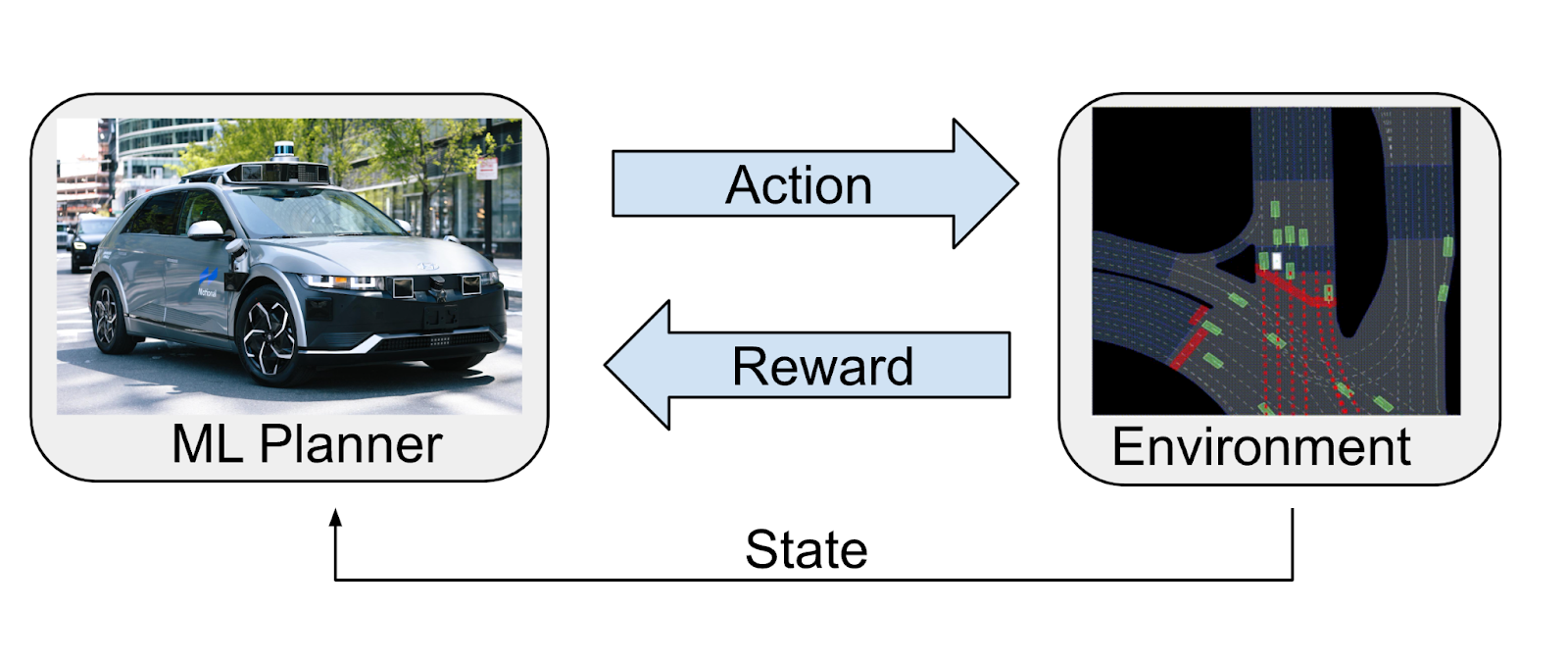
One of the greatest challenges in deploying ML-based AV systems is the open-loop to closed-loop distribution shift. Small prediction errors can accumulate over time, causing the model to drift into out-of-distribution behaviors. To mitigate this, Motional has invested heavily in closed-loop training pipelines and reinforcement learning (RL).
Key Innovations:
- Closed-Loop Multi-Step Training: Instead of training on static, single-frame datasets, we simulate the AV’s behavior over multiple time steps, training the model to anticipate and correct its own errors. However, training in a closed-loop setting naïvely is extremely costly, increasing training compute more than 10x. To address this, we invested heavily in building a ray-based distributed training infrastructure. This investment has allowed us to dramatically optimize training efficiency, reducing costs by a factor of more than 8 while maintaining high complexity and robustness in our models.
- Reinforcement Learning (RL): We incorporate explicit reward functions designed for safety, comfort, and traffic rule adherence, guiding the model towards desirable long-term behaviors. Through RL, the planner learns to navigate dynamic environments by continuously refining its decision-making based on accumulated experience.
- Causal Learning: RL enables the model to understand the causal relationships between environment, actions, and future states, reducing the likelihood of unexpected behaviors from distribution shift.
By integrating closed-loop training and RL-based fine-tuning, we ensure that our ML Planner not only performs well in offline datasets but also generalizes effectively in real-world deployment.
Data Mining and Augmentation for Real-World Scalability

Machine learning models are only as good as the data they are trained on. In autonomous driving, achieving real-world generalization requires a comprehensive dataset that captures the full spectrum of driving conditions, rare events, and complex interactions. At Motional, we have built a scalable data infrastructure that systematically mines real-world driving scenarios, focusing on high-value edge cases that challenge autonomous systems. Our goal is to ensure that our motion planning model can robustly handle nuanced behaviors across diverse Operational Design Domains (ODDs).
Rather than randomly collecting and labeling data, we employ targeted data mining techniques, including active learning and embedding clustering, to extract the most informative and challenging driving situations. Our data mining pipelines include a data linter stage that filters out data samples that are incomplete or not in desired ODDs or target capabilities. With linted datasets, our targeted data mining approach allows us to focus on high-impact scenarios that challenge autonomous systems, including:
- Stop-and-Go Traffic: Training the model to smoothly accelerate and decelerate in congested environments while avoiding unnecessary braking oscillations.
- Cut-In Maneuvers: Detecting and responding to aggressive lane changes by surrounding vehicles, requiring precise speed adjustments and proactive gap management.
- Traffic Light Interactions: Planning effective responses to complex traffic light scenarios, such as handling yellow lights or adjusting to varying intersection dynamics.
- Vulnerable Road User (VRU) Handling: Ensuring safe interactions with pedestrians and cyclists, adjusting motion plans based on their predicted paths.
- Protected & Unprotected Turns: Handling turns across traffic, yielding appropriately, and executing maneuvers with safe but human-like assertiveness.
Beyond data mining, we employ data augmentation and synthetic data generation techniques to improve generalization and robustness across diverse scenarios. Our approach to data mining and augmentation forms a continuous feedback loop for improving motion planning:
- Mine: Identify challenging real-world scenarios.
- Augment: Enhance and diversify data through spatial augmentation, domain randomization and synthetic simulations.
- Train: Feed the enriched dataset into our ML-based motion planner, improving its ability to make safe, human-like driving decisions.
- Deploy & Iterate: Test in closed-loop simulations and real-world fleets, feeding hard cases back into our data pipeline.
Scaling data collection and augmentation allows Motional to continually refine our motion planning system that not only evolves from real-world driving but also anticipates and adapts to future road challenges—bringing us closer to human-like autonomous driving.
A Step Towards End-to-End ML Autonomy
Motional’s first ML-based Motion Planning system is a critical step toward a fully AI-driven AV stack. By unifying prediction and planning through Transformer-based scene encoding, reinforcement learning, and scalable data mining, we are building an autonomous driving system that learns, adapts, and continuously improves.
As we continue to push the boundaries of AV technology, our ML-first approach is paving the way for a safer, more scalable, and more human-like autonomous driving experience.

