Many experienced drivers have likely thought at some point, "I think this other driver is going to cut in front of me," moments before the other driver does actually turn the wheel and start to switch lanes.
This awareness isn't supernatural; it's our brains drawing from years of personal driving experiences to analyze driving conditions and make a prediction necessary to keep us alert and safe.
Motional is using this same type of experiential learning to develop a prediction module, PredictNet, that gleans insight from past incidents to better predict the behavior of vehicles, people, and other agents in our driving environment, thereby increasing safety. PredictNet uses machine learning principles and a multi-task learning architecture to more accurately predict the future behaviors of surrounding agents. This information is also able to flow down to our downstream functions, improving overall vehicle performance.

Next Generation of Prediction
Prediction isn’t a new function for AV technology; every Level 4 AV has used a form of prediction to anticipate the actions of other agents in the driving environment and enable safe navigation through busy roadways.
However, prediction systems historically worked in a knowledge vacuum, basing their conclusions solely on inputs from that moment in time. This works well – Motional vehicles, for example, have driven more than 2 million miles in autonomous mode without a single at-fault accident. But Motional’s goal is for our vehicles to harness machine learning principles and get smarter with every mile they drive. So every time another vehicle cuts off our robotaxi in traffic, or a pedestrian suddenly steps off a curb, that’s a learning opportunity for our prediction models.
PredictNet takes advantage of advances in Al technology, particularly transformer neural networks, to create a next-generation prediction function that gives our vehicles a more human-like ability to anticipate unexpected agent movements.
Multi-task learning architecture
PredictNet uses a multi-task learning architecture. It consists of a scene-encoding backbone and multiple prediction heads that cover critical tasks such as predicting lane changes and potential interactions between the AV and other agents, such as vehicles or pedestrians.
PredictNet uses various scene elements as inputs, including:
- Its own state history as the “ego” vehicle
- The state history of the other agents
- A vehicle lane graph
- Location of crosswalks
- State of traffic lights
Those scene elements are encoded by PredictNet’s scene-encoder backbone into learned agent feature embeddings, which are data-based numerical representations of agents that are used by all the prediction tasks.
We have one set of prediction tasks for vehicle predictions and one set of prediction tasks for vulnerable road users, or VRUs, which include pedestrians and cyclists. Both sets include lane/crossing prediction, interaction prediction, and trajectory prediction.
Vehicle lane prediction
Knowing which lane an agent will follow is the most important piece of information an AV needs to understand while predicting and planning its actions. This makes the lane graph an important prediction feature.
In the lane graph example below, it is critical safety knowledge for the AV to detect and predict that the vehicle in the neighboring lane is going to cut over into its lane. This way the AV has enough time to slow down safely, or take any other appropriate maneuvers.
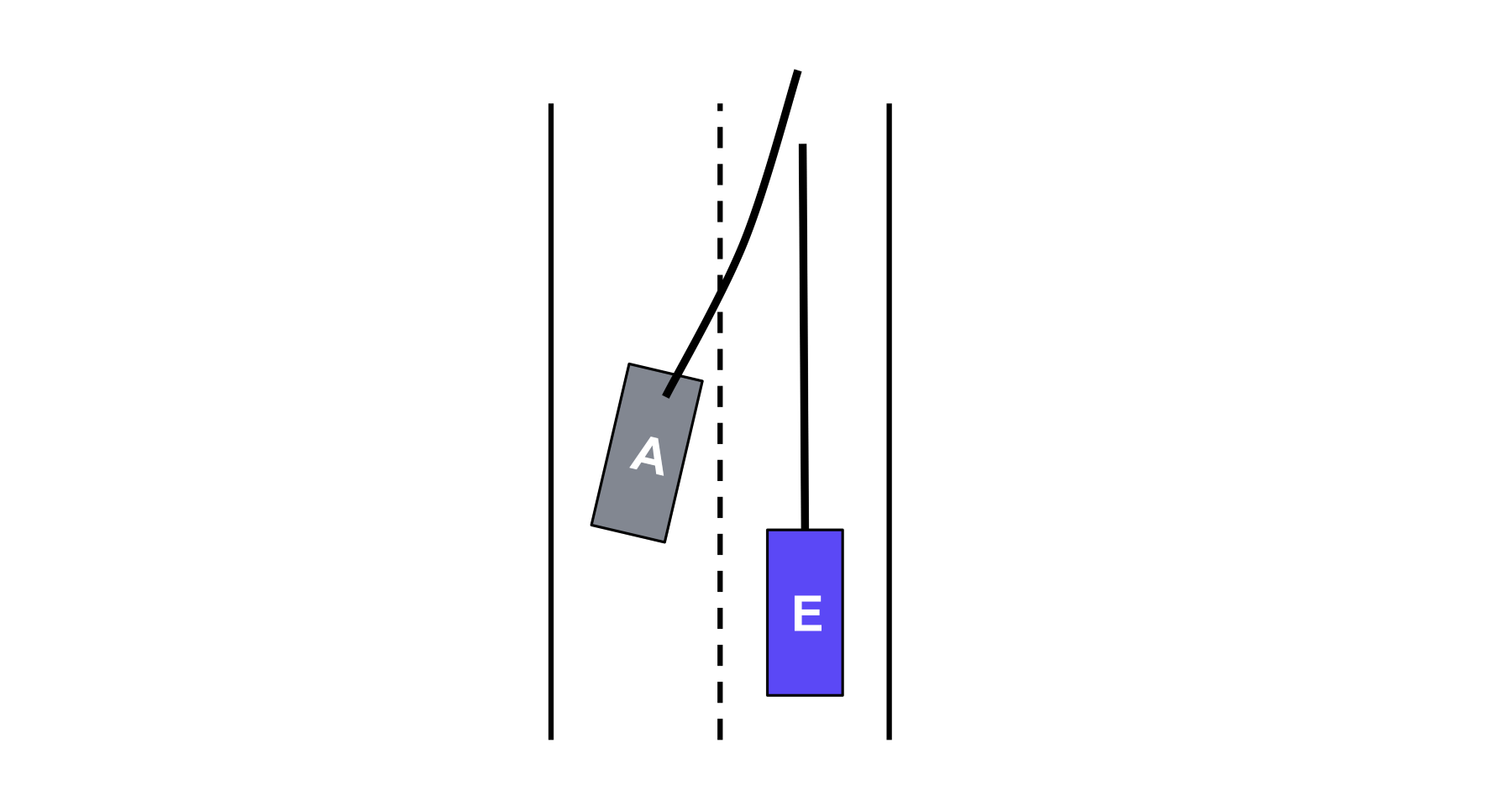
PredictNet achieves this with a lane prediction task. For each vehicle agent detected by the perception function, the lane prediction task first identifies a set of candidate lanes around the agent. Then, it uses lane feature data, such as the position and direction of the lane, as well as the data-rich agent feature embeddings from the backbone, to predict the probability that the agent will stay in its own lane or move into one of the other lanes.
We also know that human drivers can be super unpredictable. Sometimes vehicles travel out-of-control due to human error, or swerve across multiple lanes at once. In order to be robust for these types of incidents -- which we call non-map-compliant agents -- we also predict the probability that an agent won’t follow any of the candidate lanes.
Vehicle interaction prediction
After we identify the lane an agent will likely follow, it is also important to understand how it will interact with our vehicle, the ego AV. Will they cut in front of it? Or wait until it passes?
In the example below, the AV’s lane prediction module has identified that the other driver is going to make a right turn onto the same roadway. It now must predict whether the vehicle will execute the turn ahead of the AV or behind it (i.e., yield or not yield). If the other vehicle is going to yield, the AV will not need to plan to brake.
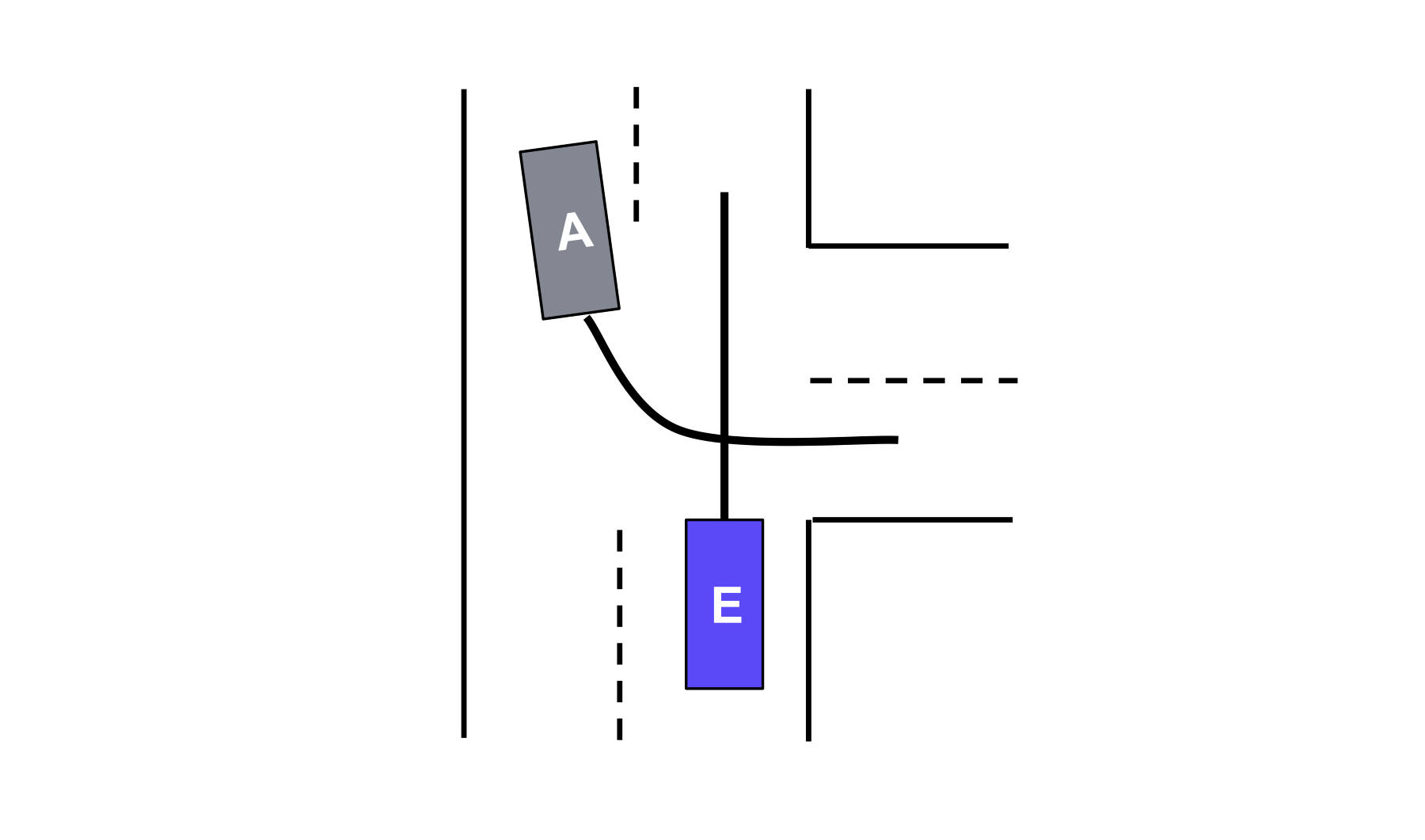
PredictNet achieves this determination with an interaction prediction task. It pairs agents –typically the Motional AV and another vehicle – and generates an interaction label based on the lanes each agent is predicted to follow.
Here’s one example of interaction labels describing a vehicle taking an unprotected left turn:
- Agent A (when following lane A) will go before Agent B (when following lane B)
- Agent A (when following lane A) will go after Agent B (when following lane B)
- Agent A (when following lane A) and Agent B (when following lane B) have no interactions
The method is generic and can be applied to any pair of agents operating in any lanes in the driving environment. But to limit computational complexity, we mainly use the interaction prediction task to predict the interactions between the Motional AV and another human-controlled agent. The task focuses on interactions that the prediction module believes will happen within the next eight seconds, which is the standard look-ahead for a prediction function. It then reassesses the scene 10 times every second.
Vehicle trajectory prediction based on lanes and interactions
Predictions aren’t guarantees, especially when human driving behavior is involved. This uncertainty is why Motional uses multimodal prediction.
The vehicle trajectory prediction task predicts the future trajectories, or positions, of other agents based on the predicted lanes and interaction labels. To achieve multimodal prediction – multiple trajectory predictions for each agent – the module will take into consideration multiple candidate lanes and interaction labels (with probabilities) and predict the likelihood the agent will take each trajectory. This at least keeps the vehicle prepared for any unexpected movements by nearby agents.
This is also where we start to see the benefit of the interconnected prediction tasks. Because the trajectory prediction module uses predicted interaction labels, a vehicle that is expected to yield at an intersection, for example, will also have a yielding trajectory.
VRU crossing intention and interaction prediction
Predicting the future behaviors of VRUs, such as pedestrians or cyclists, is critical to the safe operation of an autonomous vehicle and building trust with passengers. This can also be a very challenging task even for a human driver as cyclists swerve around traffic or pedestrians pause and look down to check their phone as they step onto the roadway.
For our AV, it makes sense to have a separate and distinct prediction task for VRUs both because of the unique roadway infrastructure set aside for them – i.e., sidewalks, crosswalks, bike lanes, and walk signals and because pedestrians can move unpredictably in ways distinct from vehicle agents, such as jaywalking or stepping out between parked cars.
In the example below, the AV needs to predict first whether the pedestrian wants to cross the street and then whether it needs to yield to that pedestrian. PredictNet has a set of tasks that are designed specifically for VRU behavior predictions.
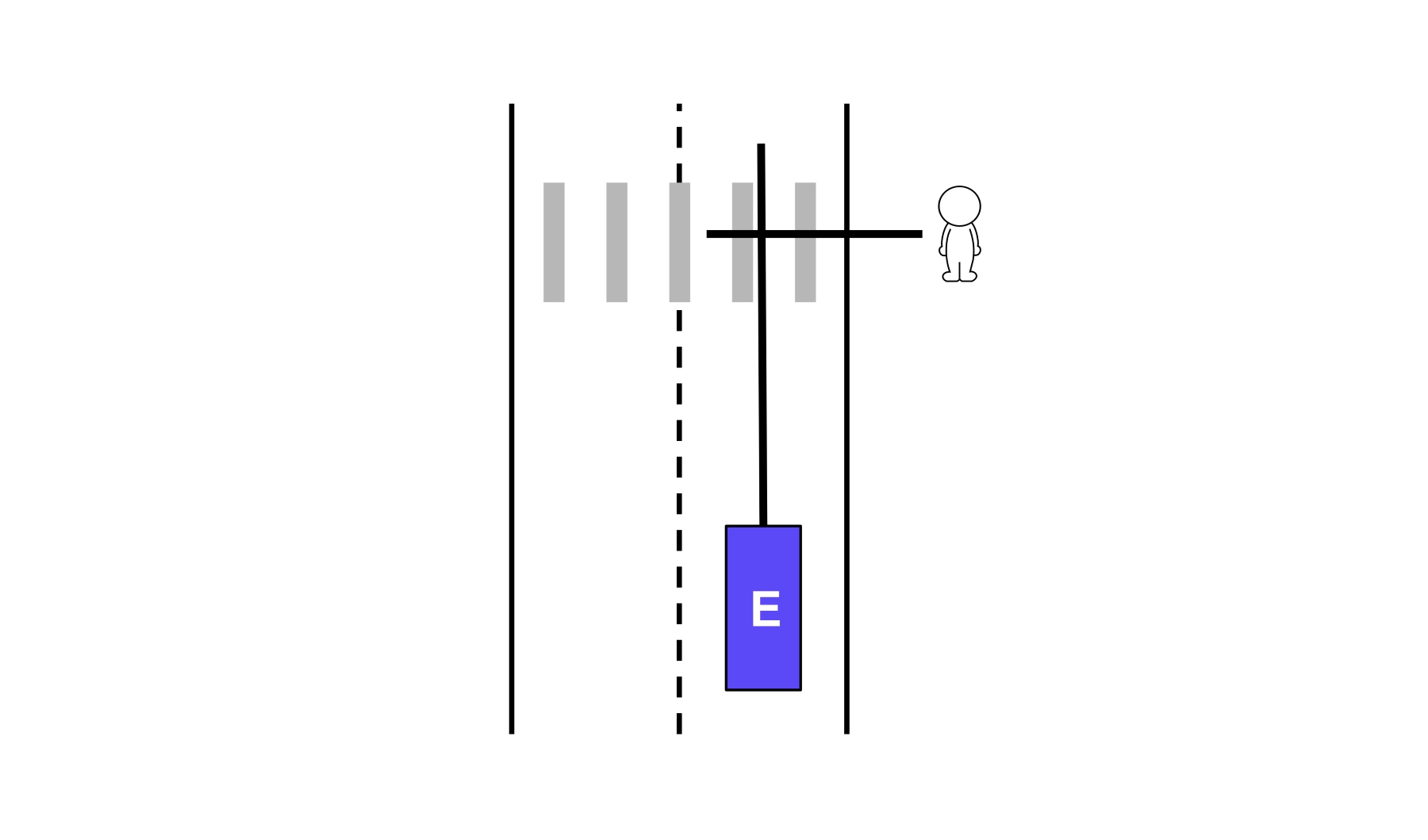
The first goal of PredictNet’s crossing intention prediction task is to predict the probability that a VRU intends to cross the road. This prediction accounts not only for VRUs crossing at marked crosswalks, but also jaywalkers.
Second, similar to vehicles, PredictNet also has a VRU interaction prediction task that predicts whether a VRU will cross ahead of or behind the AV (yield or non-yield).
Finally, the VRU trajectory prediction task determines positioning based on the predicted crossing intention labels and interaction labels.
Transformer-based backbone and joint multi-task learning
The transformer neural network architecture has been the key enabler of many recent technology breakthroughs across several different AI domains, most notably natural language processing and computer vision. We find that its architecture also works well to encode different scene elements into a common backbone. Transformers allow the model to understand the interaction between different agents, as well as between agents and the map environment – interactions that are critical for prediction tasks to work effectively and efficiently.
This form of AI benefits well when trained on large databases, such as volumes of books or terabytes of images. An AV produces large amounts of data, between all of its sensors, hardware, and software. Multiply that across an entire fleet of AVs operating every day and a large, detailed database is quickly compiled.
PredictNet employs the shared machine learning-enabled scene encoding background across all of its tasks. This means that not only does PredictNet get smarter, but those learnings are shared across each of the tasks. In turn, this makes our prediction function more experienced providing a safer and smoother ride for our passengers.
----
Motional’s Technically Speaking series takes a deep dive into how our top team of engineers and scientists are making driverless vehicles a safe, reliable, and accessible reality. Be sure to check out other entries in the series:
Part 1 -- Learning With Every Mile Driven (Continuous Learning Framework)
Part 2 -- Auto-labeling With Offline Perception
Part 3 -- nuPlan Dataset Will Advance AV Planning Research
Part 4 - Mining For Scenarios To Better Train Our AVs
Part 5 -- Predicting The Future In Real-Time For Safer Autonomous Driving
Part 6 -- Closing The Loop To Travel Back And Help AVs Plan Better
Part 7 -- Using Machine Learning To Map Roadways Faster
Part 8 -- Improving AV Perception Through Transformative Machine Learning
Part 9 -- How Continuous Fuzzing Secures Software While Increasing Developer Productivity
Part 10 -- Improving Multi-task Agent Behavior Prediction

