Motional’s Technically Speaking series takes a deep dive into how our top team of engineers and scientists are making driverless vehicles a safe, reliable, and accessible reality.
In Part 1, we introduced our approach to machine learning and how our Continuous Learning Framework allows us to train our autonomous vehicles faster. Part 2 discussed how we are building a world-class offline perception system to automatically label data sets. Part 3 announced Motional’s release of the nuPlan dataset, the world’s largest public dataset for prediction and planning. Part 4 explains how Motional uses multimodal prediction models to help reduce the unpredictability of human drivers. Part 5, looks at how closed-loop testing will strengthen Motional's planning function, making the ride safer and more comfortable for passengers.
Venice Liong, a Senior Engineer and Team Lead with Motional, also contributed to this article.
In February, a layer of snow fell on Las Vegas. When this happens, the snow usually doesn’t last long before melting, but it can briefly create a white blanket on the region’s roadways, covering over lane markings and even stop signs.
However, a light coating of snow won’t ground our fleet of robotaxis that drive along the Las Vegas Strip each day. Every vehicle’s onboard computer contains a detailed map of its operating district, including every traffic light, stop line, and bicycle lane, allowing it to operate safely even when lane stripes and road markings are obscured.
Mapping is one of the first tasks our teams undertake when we enter a new city. We create high-definition maps of the driving environment that feature centimeter-level precision and help the vehicle understand where it is, what’s around it, and where it should move next.
But creating these large, data-heavy maps currently takes tremendous time and resources. It can take months to make an HD map for a mid-sized city in the U.S., depending on the number of road miles, structures, and intersections, among other details. And accuracy is important, as the maps supply the foundational details upon which AVs make safe decisions.
This sort of timeframe will provide a significant headwind for companies looking to scale up commercial robotaxi operations quickly. Motional is using machine learning-based techniques to speed up this process, reducing the amount of time it takes to map a city from weeks to days, and enabling Motional to start serving passengers in new cities faster.
Making a detailed map
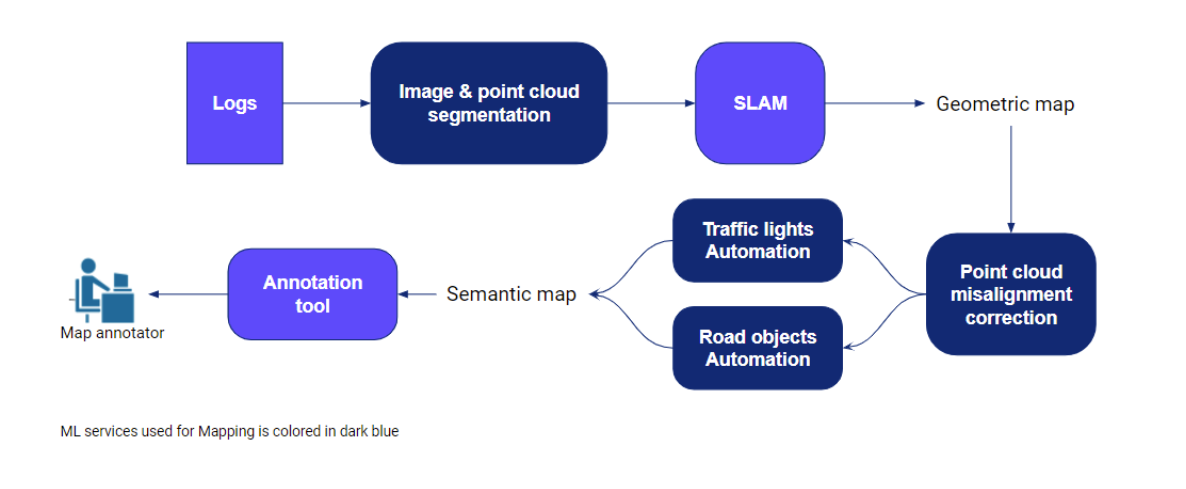
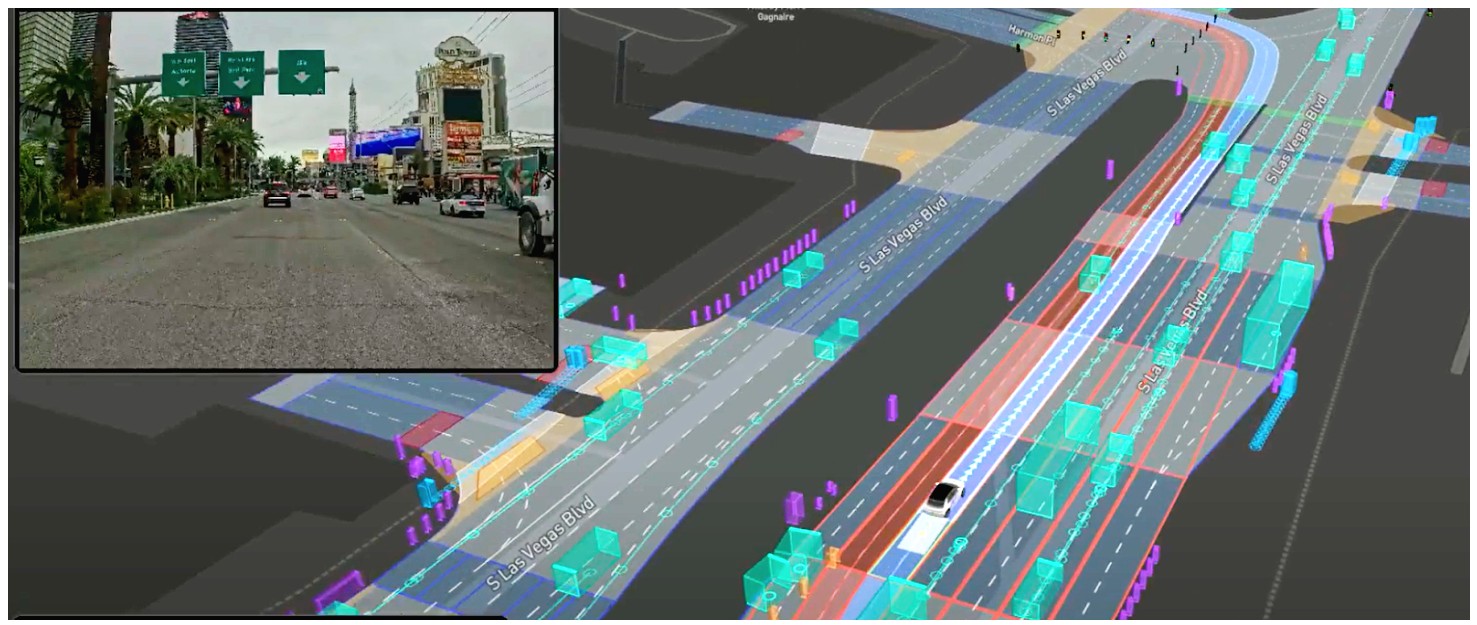
An AV collects vast amounts of data from its various sensors, such as lidar, camera, radar, etc. These sensors help generate highly precise geometric and semantic information about the vehicle’s operating district. A geometric map contains point clouds representing 3D information about a city, such as buildings, curbs, overpasses, and other streetside structures. A semantic map contains details such as driving lanes, road boundaries, and traffic lights.

Today, details from the semantic map are laid on top of the geometric map, largely by human annotators who make sure all the data points align, and that curb cuts and turning radii are accurate. Any lack of precision in the map can compromise the AV’s on-road behavior, such as poor localization. There are publications that explore map-less driving, but to strengthen the chances of successful autonomous driving, having an HD map is the approach Motional believes is best.
Here’s how we use machine learning to facilitate HD map creation for a new city.
We begin by collecting sensor data for the new city using our AVs (currently driven by trained human operators), followed by data validation, which eliminates clear data discrepancies and outliers. Next, we label the pixels and points in the data using machine learning-based image and point cloud segmentation techniques, respectively, that were built using data from previous cities.
The benefit of labeling is threefold. First, the labels make it possible to remove points corresponding to dynamic objects – cars, pedestrians, anything that will move – leaving behind the static objects – curbs, buildings, trees. Second, these labels facilitate loop closures when building the geometric map. Autonomous vehicles are able to more easily recognize landmarks they’ve passed before when they’re labeled. Third, these labels can be passed on as prior information to any downstream machine learning models, providing additional queryable data for our Continuous Learning Framework.
Transforming data into a map
Motional uses graph SLAM – Simultaneous Localization and Mapping – to create a geometric map using the labeled sensor data. Because point cloud misalignments are still possible even after running the SLAM algorithm, we created a machine learning-powered model to identify and fix these errors prior to finalizing the geometric map.
Since a map tends to be large, we cannot perform ML inference for the entire city map without running up against memory constraints. Instead, machine learning engineers infer the model predictions on portions of the map, and then combine them together.
We also automate traffic light annotations in the geometric map, along with annotations of other road objects such as curbs, driveways, overpasses, and traffic barriers. We do this by employing classic computer vision and machine learning in a two-step process. First, we identify traffic lights in images using machine learning-based object detectors. Then, we project 3D points onto an image and select those that correspond to traffic lights. The chosen points are carefully processed to form clusters of traffic lights, which are continuously associated across time for refinement.
The maps help the AV in several ways. Pre-stored information of lanes assists the Planning module, ensuring the vehicle stays in the travel lanes and follows traffic rules, even when a lane marking is obscured by a covering of snow, or maybe some debris. Traffic lights detected online can be matched with those on the map to provide the vehicle with situational awareness. If they’re not on a map, the vehicle could miss a traffic light – particularly in an urban city like Las Vegas where the streets are lined with colorful lights.

Motional’s machine learning models are run on the cloud for scalability. While our AVs are well-equipped to collect data, we prefer to allocate finite compute resources to our core AV functions. By moving mapping activity to the cloud, we are less bound by latency constraints, and have more leeway in experimenting with the model architecture, allowing us to prioritize model accuracy.
Assisting annotators and learning continuously
Human annotators can still generate mapping labels themselves during the quality control process. If annotators are not satisfied with the machine learning-generated annotations – perhaps a predicted lane divider is misaligned with the actual one in the road – they adjust the labels, which then provides valuable continuous learning feedback and improves the machine learning models.
From a recent internal study, we found that using one type of machine learning tool reduced the amount of time required for human annotators to add semantic information by 21%.
Unlocking AVs’ Potential
Autonomous driving has the potential to revolutionize mobility. But this can only happen if AV technology can be smoothly, quickly, and safely extended to new cities. In an ideal scenario, the mapping pipeline should be a plug-and-play system, consuming raw sensor data from Motional’s robotaxis as they take initial test drives around a city and producing an accurate, highly detailed map quickly.
Heeding that, we are developing groundbreaking machine learning technology to enhance mapping. Once fully trained by human annotators, a machine learning-based mapping module should be able to reduce the amount of time it takes to map a city from weeks to days, enabling Motional to start serving passengers in new cities faster.
We invite you to follow us on social media @motionaldrive to learn more about our work. You can also search our engineering job openings onMotional.com/careers

