Welcome to Motional’s Technically Speaking series, where we take a deep dive into how our top team of engineers and scientists are making driverless vehicles a safe, reliable, and accessible reality. In Part 1, we introduce our approach to machine learning and how our Continuous Learning Framework allows us to train our autonomous vehicles faster.
Anyone who has extensively driven has inevitably been surprised by a pedestrian suddenly stepping out between parked cars into the street. Years of driving experience teaches us how to safely handle such a situation without too much thought. We know when driving down a road to be aware of pedestrians, to keep an eye out for someone stepping between parked vehicles, anticipating whether they might step out between the cars into the roadway, and having a plan to safely stop.
Part of the challenge of developing safe autonomous driving systems is training vehicles how to respond to rare, but challenging, situations like a skilled human driver. We’re already well on the way toward solving for these types of incidents, which we refer to as edge cases. Motional engineers have been able to advance autonomous vehicle(AV) technology to the point where our driverless vehicles have driven 1.5 million miles and completed 100,000 passenger trips on public roadways – without a single at-fault accident.
However, to perfect our technology and develop a global network of autonomous robotaxis with our ride-hailing partners we must develop machine learning-based technologies capable of quickly training our vehicles at an unprecedented scale. We’re doing this through our Continuous Learning Framework (CLF), which uses machine learning principles to make our fleet of AVs more experienced and safer with every mile they drive.
While the Autonomy team at Motional is known for the popular nuScenes Challenge and their groundbreaking work on machine learning-based object detection and segmentation with PointPillars, PointPainting, and most recently PolarStream, we want to give a sneak peak into the lesser-known, cloud-based infrastructure at Motional that powers those machine learning models.

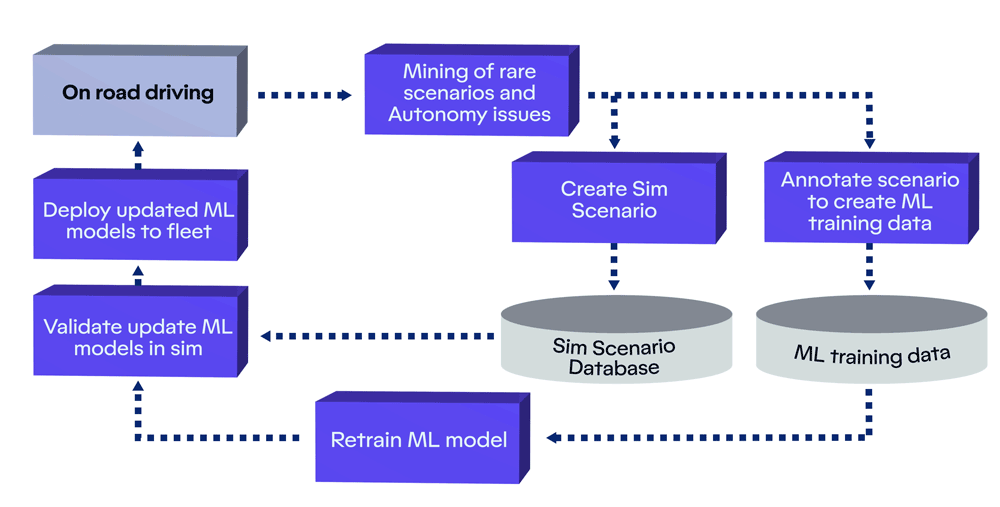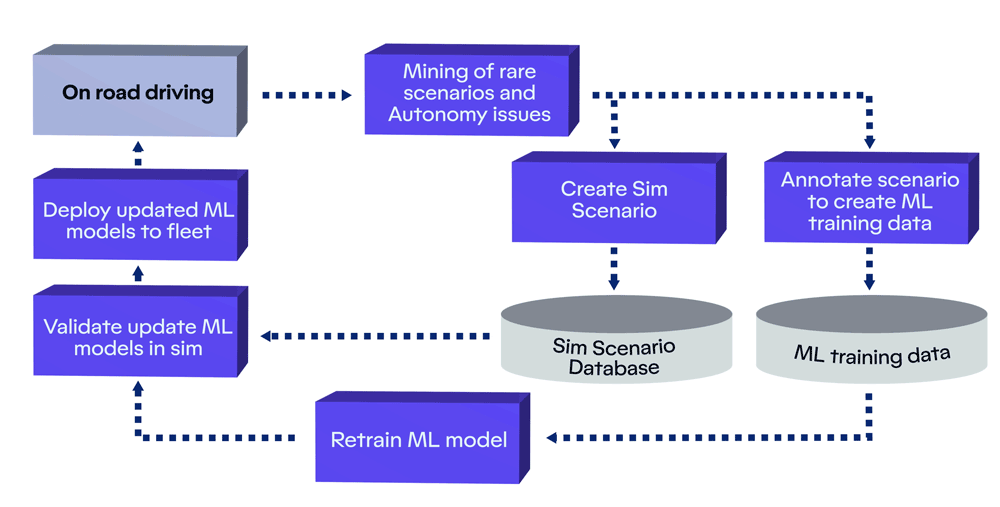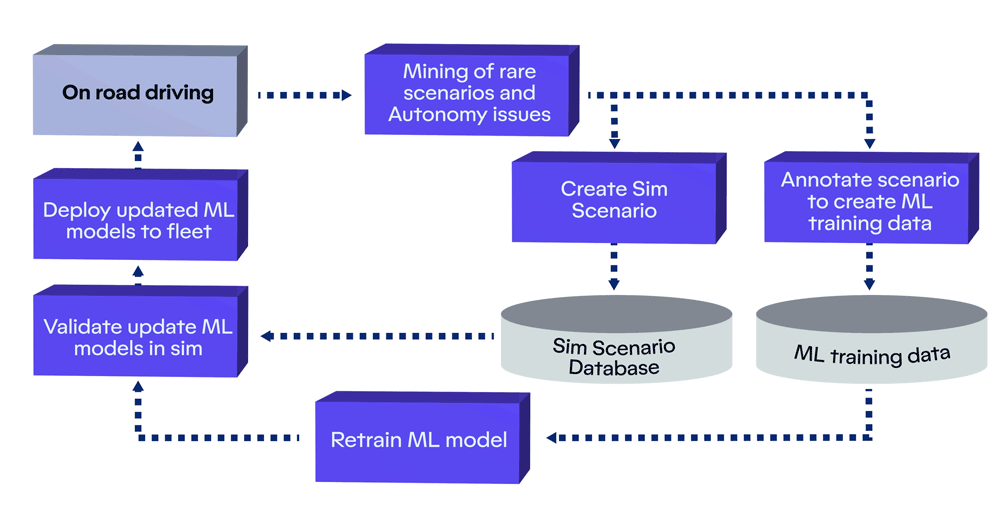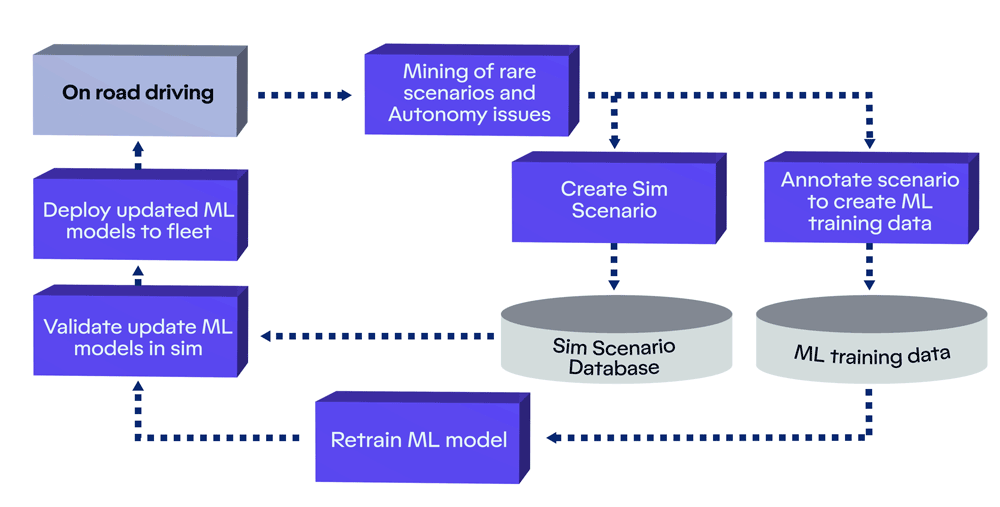
Motional’s Continuous Learning Framework that enables our AI-first autonomous driving stack to automatically improve with every mile we drive.
Creating a Flywheel Effect
Driving can be uneventful – even boring. The vast majority of the time, driving from Point A to Point B can feel like second-nature. But that other fraction of time behind the wheel can involve a broad range of rare and unique driving experiences - those edge cases. Examples of edge cases include obstacles in the roadway, pedestrians darting into traffic, racing trikes, and other objects we don’t encounter every day.
At Motional, we built an AI-first Autonomy stack that requires large amounts of high-quality, annotated data for training. However, to properly train the AI system, simply having large volumes of data isn’t sufficient; the training data, more importantly, needs to be well-balanced and representative of rare cases.
Let’s take object detection as an example: At one point, the value of adding more training samples featuring regular sedans will only marginally improve detection performance involving standard cars. However, adding a rare example of a futuristic-looking racing trike vehicle may be incredibly beneficial to boosting detection performance.


Building a safe driverless system requires us to detect, classify and predict rare agent classes, such as racing trikes or pedestrians in feather costumes that we may encounter on the Las Vegas Strip. Our Continuous Learning Framework enables us to specifically boost the performance of the AV stack when they encounter rare occurrences such as these.
Motional’s Continuous Learning Framework (CLF) is a system that finds those rare edge cases in the large volume of data that we collect every day from our fleet. This holistic framework employs a number of key steps: mining for rare cases, creating training data through automatic and manual data annotation, retraining our machine learning models using that data, and evaluating the updated models at scale.
This may sound a bit abstract, so let’s use the example we mentioned earlier: occluded pedestrians that may move out between two parked cars. This is one particular example where we are successfully applying our CLF. It’s a challenging example because our vehicles need to detect pedestrians even when they are largely occluded. Even more challenging is the need to reliably predict the likelihood that the pedestrian will step out between the vehicles. And to make matters even more complex, the pedestrians may not actually look like regular pedestrians - we see pedestrians dressed up as all sorts of characters or animals in Las Vegas.

Motional developers can combine a large number of attributes in SQL queries to mine for complex and rare scenarios in minutes. This is an example of how we mine for jaywalking pedestrians in close distance to our AV where our prediction system created suboptimal predictions.
For this particular example, we use the scenario mining framework to mine for agents that our perception system had trouble detecting or predicting that the largely occluded object our vehicle passed by was actually a pedestrian. In case of a bad detection, we send the scene to our human annotators to create training data for our detection models. In case of bad prediction, we can actually use our high-quality offline perception system to create automatic training data in the cloud.
Motional’s Scenario Search Engine allows developers to quickly search Motional's vast drivelog database and introspect and visualize the results in seconds.
This scenario query can run every time our autonomous vehicles are on the road collecting data. When we collect a sufficient number of samples and expand our training data, we can then retrain the machine learning models. If we show through simulation and modeling that performance has improved on our dedicated pedestrian handling dataset, as well as our overall dataset, the models can then be redeployed to the vehicles.
Essentially, we have built this machine learning-based flywheel that allows us to automatically improve performance as we collect more data - and it does this by specifically targeting the rare cases. Our CLF works like a closed-loop flywheel: each step in the process is important, and completing one step advances the next step forward. The entire system is powered by real-world data collected by our vehicles. As the inflow of data coming from our vehicles grows, the flywheel will turn faster, making it easier to accelerate the pace of learning, solve for edge cases, map new ODDs, and expand into new markets.
A Holistic Approach
Motional engineers and scientists are taking a holistic approach to our CLF. We’re not advancing system perception, prediction, planning, training, and simulation in self-contained silos – the success of each element depends on the success of the others. We are very excited to share more details in the upcoming weeks on the various components of the Motional CLF: from how we built the mining engine and framework and create high quality labels using our cloud-based offline perception system, to how we validate our system at scale and share use-cases where we applied this framework successfully.
Changing the future of transportation requires us to clearly demonstrate that driverless robotaxis – guided by machine learning and advanced neural networks – can navigate complex, dynamic road environments better than the best human drivers. With a Continuous Learning Framework as a foundation to improve our AV tech stack with every mile driven, Motional is creating the safest driver possible.
We invite you to follow us on social media @motionaldrive to learn more about how we’re making driverless technology safe, reliable, and accessible. You can also search our engineering job openings on Motional.com/careers.

