Motional’s Technically Speaking series takes a deep dive into how our top team of engineers and scientists are making driverless vehicles a safe, reliable, and accessible reality.
In Part 1, we introduced our approach to machine learning and how our Continuous Learning Framework allows us to train our autonomous vehicles faster. Part 2 discussed how we are building a world-class offline perception system to automatically label data sets. Part 3 announced Motional’s release of the nuPlan dataset, the world’s largest public dataset for prediction and planning. Part 4 explains how Motional uses multimodal prediction models to help reduce the unpredictability of human drivers. Part 5 looks at how closed-loop testing will strengthen Motional's planning function, making the ride safer and more comfortable for passengers.
Building an autonomous vehicle (AV) capable of safely navigating its way through busy public roadways requires developing a high-performing perception system capable of quickly and accurately understanding what’s happening around the vehicle.
Motional’s IONIQ 5 AV robotaxi needs to be able to quickly distinguish between real-world objects, such as an actual pedestrian on a sidewalk, and not-real ones, such as a high-res photo of a person on a wall poster. Cameras are one of the primary sensors we use for this task, along with LiDARs, radars, and other audio and ultrasound sensors.
Transformer Neural Networks (TNNs) are helping Motional’s onboard perception system sift through the background noise to classify and properly bound objects around the ego vehicle, allowing the AV to predict future object movements and plan a safe course forward.
Up to now, the tradeoff has been that TNNs consume more computing budget and can’t process fast enough to be relevant. However, our research shows that using specific strategies can significantly reduce TNNs run-time, enabling them to run on our AVs without significantly losing performance.
A 360 VIEW
Human drivers wouldn’t be operating safely if they only looked through the front windshield. It’s why all vehicles come with rear windows, side windows, rearview mirrors, and side mirrors. Most also now have backup cameras.
AVs go even further, however, with enough cameras to provide a 360-degree view of the entire vehicle. This surround-view setup is critical to allow the perception function to holistically reason out what’s happening around the vehicle.
Here is the camera and perception sensor setup that we used to capture data found in our popular nuScenes dataset:
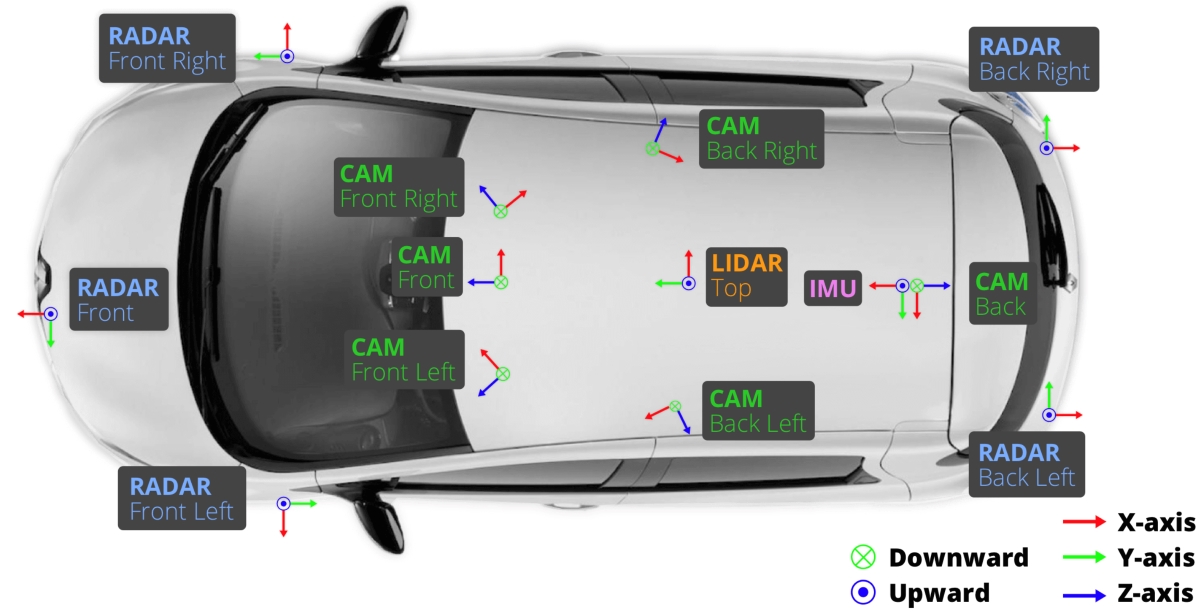
The above setup includes:
- 6 Cameras
- 1 LiDAR
- 5 RADARs
- 1 IMU sensor
(Note: This image is not a representation of how the sensor suite on current Motional robotaxis is laid out.)
The cameras are positioned in a way to allow the vehicle to see everything in front of it, behind it, and to the side of it.
TRANSFORMERS VS CNNS FOR VISION
Convolutional Neural Networks (CNNs) have been the cornerstone of computer vision for many years. CNNs excel at capturing local spatial patterns and hierarchical structures in images, thanks to their convolutional and pooling layers.
On the other hand, transformers were initially developed for Natural Language Processing tasks but have since been extended to computer vision. Transformers are known for their ability to capture global dependencies and long-range interactions within the data. This makes them well-suited for tasks that involve complex relationships between image elements, such as semantic segmentation, where understanding global context is crucial.
In our AVs, transformers can leverage this long-distance attention module to effectively block out background noise and focus on what’s important. TNNs make better predictions due to their capacity to capture long-range dependencies, and their ability to generalize well when provided with larger data samples, as seen with Large Language Models and Chat-GPT. Fortunately, Motional has millions of samples of supervised data on which it can train TNN-based perception algorithms.
LIMITATIONS WITH TRADITIONAL CAMERA PERCEPTION
Historically, our AVs’ perception systems processed each camera image individually, meaning we ran CNN-based networks for each camera without any context sharing. A single camera obviously can’t capture all 360 degrees around a vehicle. To stitch together the field of view from multiple cameras, Motional used a hand-tuned filtering algorithm that combined duplicate detections from adjacent cameras.
This approach worked decently but had limitations. Specifically, it had difficulty accurately detecting objects that span across multiple cameras. We didn’t have enough perspective or a higher receptive field (in computer vision terms) than what a single camera can capture. Also, there’s an issue with duplicate detections; oftentimes, the perception system perceives an object visible in both cameras as two separate objects.
Here’s a visual example of the real-world challenges AV perception systems face:

Just by looking at this image and lacking any additional context, it is unclear to the onboard computer what this object is. It could be a barricade, a bus, a train - any number of things. We also are unable to tell how long it is. Does it end just outside the camera field? Does it go on for a city block?
At this point, our system doesn’t have enough context to either classify the object or define the object’s boundaries – two essential perception tasks.

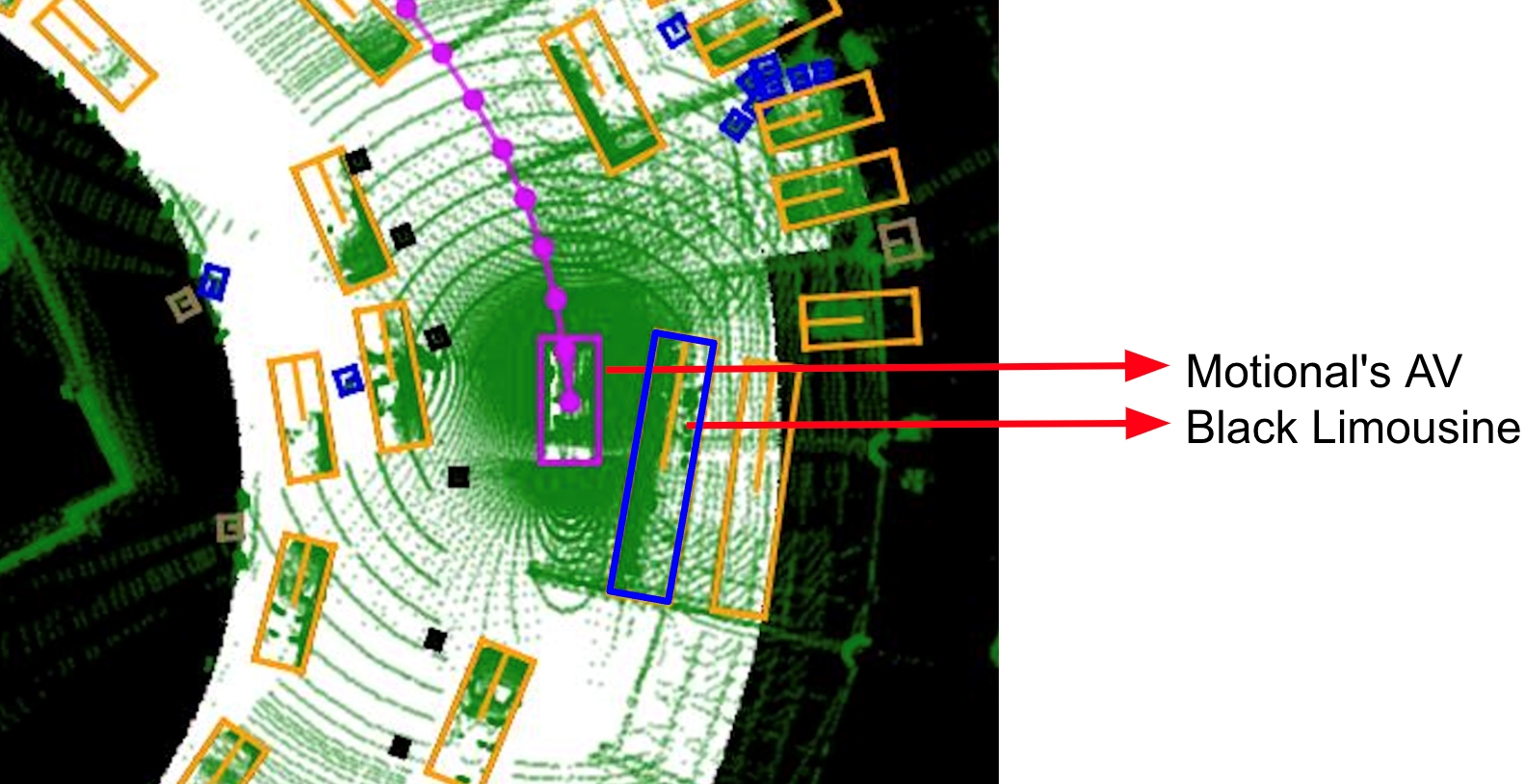
When we add one more camera image, the object starts to come into view – it’s clearly a stretch limousine. However, we still have no idea how much further in the right direction this object extends. And in Las Vegas, where we operate our commercial robotaxi service and where these images were taken, stretch limos can be very long.

With these three camera views, the vehicle’s perception network now has all the information and context needed to classify the object, as well as bound it properly.
TURNING 2D INTO 3D
Simply capturing an object with a camera isn’t good enough to support a highly functioning perception system, nor downstream tasks such as trajectory prediction and motion planning. Instead, we must convert that two-dimensional, street-level image into a 3D object viewable from overhead. This is because Bird’s Eye View, or BEV, representations of objects clearly present the locations and scale of objects around our vehicle.
Here’s how that stretch limo looks in Bird’s Eye View (BEV):
It’s in this process of stitching together camera images and converting them into BEV representations where Transformer Neural Networks really shine. Motional uses Surround-View Image Networks, which is built on TNN, to convert our vehicle’s camera inputs into a BEV output.
Processing images in the BEV space, like fusing temporal information and fusion of features in BEV, gets better when combined with data from LiDARs, which natively have BEV-based features.
Let’s visualize what a surround-scene looks like for Motional vehicles and how it looks all together:
However, TNNs suffer from high compute budget requirements making them challenging to use in online AV perception systems – so far.
BRINGING SURROUND-VIEW IMAGE NETWORK LIVE ON-CAR
The biggest obstacle to using TNN on AVs has been the inference time. To give more context, the baseline TNN that we started off with was taking 2.5X more time than what’s practically feasible to provide timely situational information. Our sensors can provide us input information at 20Hz, so our end-to-end pipeline was bottlenecked by our perception algorithm. Fully unleashing the state-of-the-art capabilities of AVs requires a faster inference time.
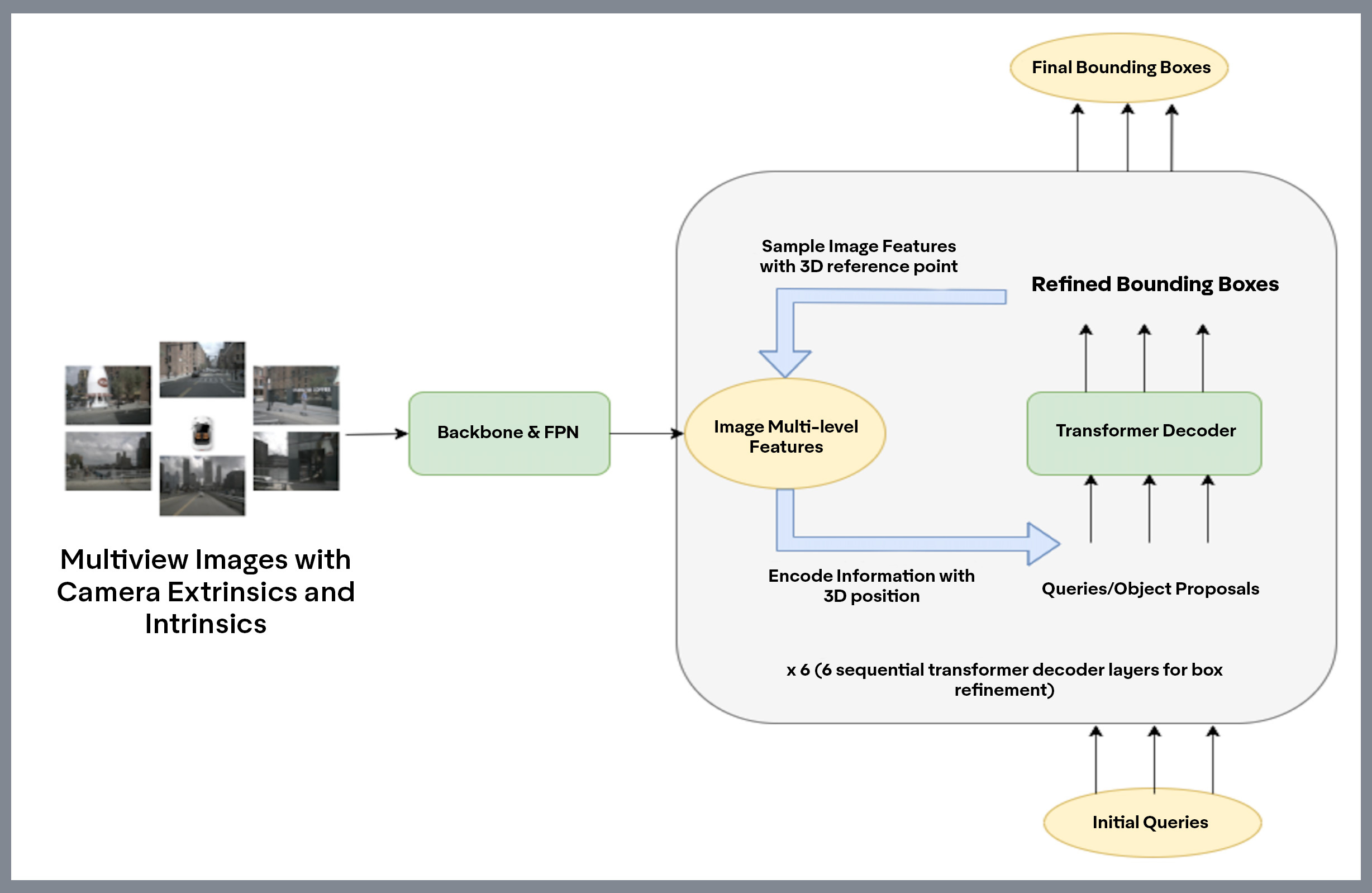
In our recently published paper “Training Strategies for Vision Transformers for Object Detection,'' which was accepted at the CVPR’23 Workshop on Autonomous Driving (WAD), we evaluated a variety of strategies to optimize inference-time of vision transformers-based object detection methods while also keeping a close watch on any performance variations. These experiments include reducing input resolution, adding image pre-croppers, tweaking query embedding dimensions, and post-processing steps, among other strategies. We validated these learnings on our deployment hardware with a TensorRT module.
Through these strategies, we were able to improve inference time by 63% at the cost of a mere 3% performance drop, demonstrating that transformers can become a primary enabler of high-performance AV perception systems. In addition, while deploying this network on our Motional cars, we perform in-house network pruning and quantization strategies to improve the runtime even further.
A SAFER AV
For robotaxis to operate safe and comfortably, AVs need a robust perception function. The faster our vehicle identifies what’s happening around it, the less our vehicle will have to stop quickly or use other evasive maneuvers.
The arrival of TNNs as a viable machine learning engine brings additional context to our perception modeling without overwhelming the onboard compute. By embracing this next-generation technology, Motional is able to deploy the best machine learning arsenal, the transformers, on our cars.
We invite you to follow us on social media @motionaldrive to learn more about our work. You can also search our engineering job openings on Motional.com/careers

