Autonomous vehicles (AVs) generate enormous amounts of data while out on the road, logging hundreds of thousands, even millions, of data points during every hour of operation. This volume of data is needed to properly train and validate the machine learning models that allow Motional robotaxis to operate safer than the best human driver.
However, it's impossible for humans to keep track of what is contained within all the gathered data and determine whether any of it is useful. As a result, Motional designed a scalable system capable of finding the edge cases hidden within this mountain of data that can then be used to improve our training and testing datasets and validate behaviors.
Our Challenge
AVs are already very capable of handling routine driving functions, such as traveling down a stretch of road, stopping at red lights, and allowing a clearly visible pedestrian to cross the street. It’s the unusual or complicated driving encounters - a pedestrian stepping out between cars, for example, or a flat-bed truck changing lanes - that our systems must be trained to handle safely using our Continuous Learning Framework. For example, since we expanded to Santa Monica, we suddenly have a lot more pedestrians carrying surfboards - something we didn’t have previously in our datasets from Las Vegas, Boston, Pittsburgh or Singapore.
Beyond finding edge cases in our existing driving domain, the Continuous Learning Framework allows us to also quickly scale our city footprint: we can leverage that system to automatically detect and mine for perception or prediction errors in a new city or environment, automatically create ground truth labels, and then improve our ML models on the vehicles with that training data.

On the left, we can see objects missed by the online perception system, compared to the offline auto-labeling system, which is on the right. These missed objects are converted into attributes that are easily queryable through the scenario mining framework. In addition, all missed objects create a specific dataset that our models are then trained on.
Scalable Pipeline For Attribute Annotation
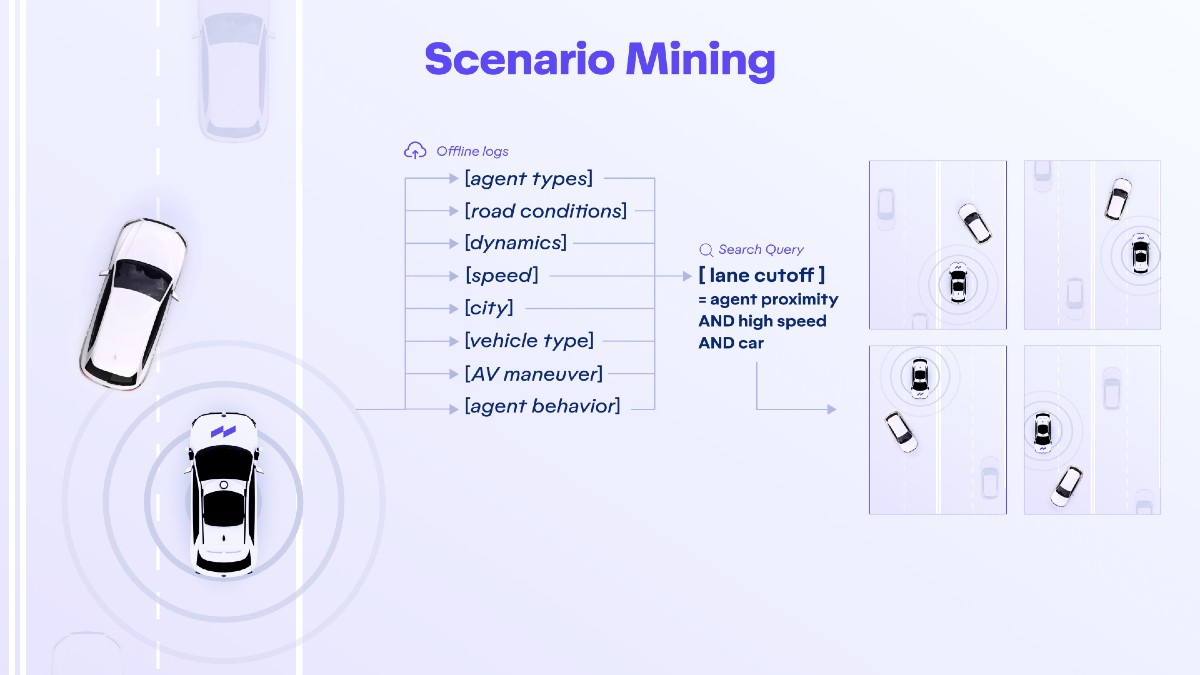
As we increase the size of our fleet and start to produce more and more data, it’s critical that we are able to scale up the data mining process to keep the Continuous Learning Framework turning. This mining pipeline starts with logs generated by our AVs. The logs contain the output from sensors - lidar point clouds, images, and radar detection, for example - in addition to storing the intermediate results of the AV software pipeline. These intermediate results include online agent detections, intent of planner, or predictions of the environment. All of this data is used as the input into the scenario mining pipeline for attribute computation.
These logs are processed with our machine learning-powered offline perception system to automatically create ground-truth labels from the raw sensor data. Those ground-truth labels are then used to compute attributes for every single instance in a log, creating a semantic description of the environment that’s stored in a searchable database.
What our systems annotate is limited only by our own imagination; because the annotation is performed offline in the cloud, there’s virtually no computation requirement imposed. We currently annotate hundreds of searchable attributes that are sorted into different sections based on the inputs they require and their representation. For example, the attributes can either be in relation to the state of the AV (vehicle speed, vehicle lane occupancy, vehicle proximity to lane boundary), or they could be based on an agent in the scene (whether it was a car, truck, or pedestrian; the euclidean distance of the agent to the AV; the lane the agent was in; or simply the speed the agent was traveling).
A diagram outlining the processing pipeline from vehicle outputs, into labeled attributes, and then into query-able scenarios with corresponding scene visualization.
In addition to simple hand-picked attributes, the Continuous Learning Framework can also be used to find detection and prediction errors between the online and offline perception systems. As our online prediction system is deployed in a new environment, such as a new city, we want to be able to quickly detect the different behaviors of other agents, so we compare the online predictions to the offline auto-annotated data. These two trajectories are then turned into various attributes representing errors, such as distance error, heading error, or even a false-positive AV interaction. Having a tailored dataset containing only scenes with large errors in challenging scenarios is highly valuable for training purposes.
It is very important for every AV to detect all objects in a scene reliably. For that reason, we also annotate all non-detected objects, generic objects through comparison of the powerful offline perception system with the online detections. In this way, we can create specific datasets with problematic scenarios through a simple database query. Furthermore, this allows us to tailor a machine learning model’s loss function to penalize specific errors related to the dataset.
Enabling Software Validation Through Simulation
Once we make improvements to the machine learning models, it's critically important that these changes are validated before they are deployed to the AVs. For every mile driven on public roads, an AV performs a large number of miles in simulation running through generated scenarios. This allows Motional to quantify the robustness of the AV’s models, as well as identify any possible areas of regression elsewhere in the model — before the vehicle hits the road.
An important component of completing these simulations is choosing the appropriate scenarios. Choosing uninteresting, unchallenging scenarios, such as driving on an empty highway, won’t help catch a regression. A robust data mining pipeline featuring thousands of hours of well-annotated driving logs allows us to select scenarios based on problem areas that popped up during real-world driving experiences. These can include, for example, brake taps, swerving, or even safety driver take-over. As a result, we can create a scenario query that uses those same attributes, such as whether an agent cut in front of the AV, the agent’s velocity, the lane it was in, and its position relative to the AV.
Creating a Product
Running the mining framework on large amounts of data every day requires all components - log ingestion, auto-labeling, attribute annotation, retraining and validation - to work seamlessly together 24/7. At Motional, we deploy all the tools into the cloud, and make sure that their down-time is close to zero, and if a problem occurs, it can be quickly traced and resolved.

A sample query used to mine for scenarios containing a car cutting in front of our AV.
Thanks to the scenario mining approach, which is a part of the Continuous Learning Framework, Motional cars are improving automatically with very limited human intervention.
This system allows independent faults of an AV system to be quickly detected, categorized, and curated into problematic datasets that are used to continually measure and validate Motional’s overall software stack, and thus, make our cars safer.
We invite you to follow us on social media @motionaldrive to learn more about our work. You can also search our engineering job openings on Motional.com/careers.

