Motional’s Technically Speaking series takes a deep dive into how our top team of engineers and scientists are making driverless vehicles a safe, reliable, and accessible reality.
In Part 1, we introduced our approach to machine learning and how our Continuous Learning Framework allows us to train our autonomous vehicles faster. Part 2 discussed how we are building a world-class offline perception system to automatically label data sets. Part 3 announced Motional’s release of the nuPlan™, the world’s largest public dataset for prediction and planning. Part 4 explains how Motional uses multimodal prediction models to help reduce the unpredictability of human drivers. In Part 5, Caglayan Dicle takes a look at how closed-loop testing will strengthen Motional's planning function, making the ride safer and more comfortable for passengers.
As human drivers, we’re always learning based on past performance. For example, we may ask ourselves, “Did I take that right-hand turn appropriately? Was it too sharp? Or too wide? Should I have taken it faster or slower?”
However, we can’t press rewind and make the turn again. We just have to keep it in mind for next time and try to do better.
Autonomous vehicles (AVs) also learn based on past performance. However, what if we could go back in time; how much more efficiently could we learn and improve? This will allow us to improve our AV software faster and make passenger rides safer and more comfortable.
The planning module transforms inputs from other functions - such as maps and perception - into the actions and behaviors that navigate a vehicle along a public roadway. Planning is arguably the function with the most consequential significance, as it literally gives the vehicle instructions on where and how to move. It takes all the collected wisdom from the perception and prediction modules and determines how the ego vehicle should behave in the next couple of seconds. Every 1/10 of a second, the planning module reflects on where the vehicle is, was, and should be to make sure the control module – which controls steering, acceleration, and braking – is doing what it's supposed to.
Motional engineers are developing a closed-loop training system that will allow our planning module to recognize when it takes a turn too sharp, go back in time, identify the root cause of the error, and make an immediate correction.
Using data to create a better ride
Dynamic roads present complex challenges for AVs. While it’s critical to ensure safety across all of an AV’s hardware, software, and computing components, the planning function needs to be comfortable and efficient, as well as safe. Passengers inside the AV may feel differently about a sharp right-hand turn than a turn that is more rounded and smooth.
At Motional, we believe we can address this complexity through a machine learning-first approach that enables our vehicles to get smarter with every mile they drive. Data is the key to scaling this across a growing fleet of robotaxis, and we design our technical ecosystem around this mindset.
An effective ecosystem starts with a high-quality data collection and curation engine. At Motional, we have been collecting top-quality driving data from different cities in the U.S. and Asia. We recently released some of this data with nuPlan™, the world’s largest publicly-available human-driving dataset. This data, which includes 1,500 hours of driving data, is diverse, expert-driven, and goal-oriented, making it valuable for planning. This allows us to curate planning-centric datasets with little effort and shorter wait times.
Through the loops
The next key component of an effective ecosystem is the training regimen. Typically, machine learning-based planners use an open-loop approach where the planning module does not receive real-time feedback about its output, called the intended future trajectory. During training simulations, the planning module is allowed to follow its intended future trajectory and incur errors, such as hitting a curb. Sometimes errors are introduced artificially through data augmentation, where the ego vehicle is pushed or nudged off course.
In either of those cases, the planning module has no direct way of automatically going back and making an exact correction. Instead, it learns to reduce some of those errors over multiple future iterations. It’s like discovering your toaster temperature is set too high: you can't go back and unburn the toast, you can only adjust the toaster temperature for the next slice of bread. Depending on the complexity of the scenario, this learning process can take time.
An alternative approach uses closed-loop training to give the planning module the ability to go back into the past and correct the root cause of the error. Closed-loop training produces a self-correcting planner that needs fewer parameters, less data, and fewer iterations to achieve the appropriate driving behavior. Consider the above example: with a closed-loop planner you can quickly “unburn” the toast and learn the exact optimal temperature setting moving forward. This way, the planner eventually learns how to fix a specific error as well as how to avoid it in the first place.
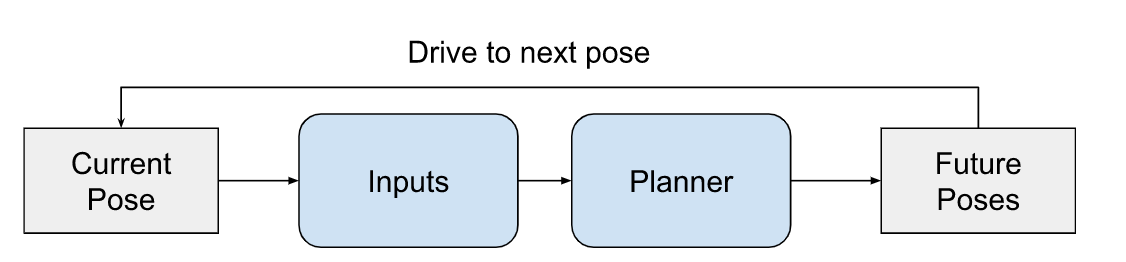
Figure 2. Planning loop. The loop starts with the current pose or state. Based on inputs from the perception and prediction functions, the AV’s planner devises a course of action to get to the next pose. That plan is executed and the loop begins anew.
Traveling back in time
In a machine learning-based planner, time traveling is enabled through what is called “differentiable simulation.” During a simulation, the ego vehicle is shifted from one location to another in a given environment over a period of time. In a differentiable simulation, the ego vehicle is shifted in a mathematically differentiable manner.
Historically, learning-based planner architectures have used rasterized images to represent the ego vehicle and all objects in its environment. The problem is that rasterized images are not differentiable. One recent solution has been to use vectorized raster images, the elements of which are connected mathematically and can be manipulated by changing inputs and outputs. In a vectorized raster image, we can move around the ego vehicle through simple translational and rotational operators.
As a course of action is executed during closed-loop training, inputs - such as vectorized raster images - and outputs - the vehicle’s intended future trajectory, for example - are recorded for each moment of time, known as a time step. We then compare the pose difference between the ego vehicle in the simulation and data collected from our expert human drivers. This pose difference is calculated as the imitation loss.
The imitation loss generates a correction signal, which is then sent back through the outputs to the inputs in a process known as backpropagation. The correction signal travels to all past time steps updating not only the trainable parameters but also the vectorized representation of the AV – its locations and poses – eliminating the erroneous initial conditions and actions.
In other words, the planner learns not only how to travel back in time to fix errors but also how to avoid them in the future.

Figure 3. Closed-loop training. The simulated course of action is unrolled and after a certain amount of time (represented by n) a loss is calculated by comparing the pose state against data collected by Motional's expert human drivers. The backpropagation signal then travels back across past time steps, correcting past maneuvers that caused the loss.
There are other differentiable input representations that all have varying strengths and weaknesses. However, Motional believes that the closed-loop training regime could likely become industry best practice and spark additional innovative input and architecture designs in near future.
Keeping passengers in mind
Planning is the ultimate module for passenger safety and comfort. It takes everything the vehicle has learned from the perception and prediction modules, as well as data from internal maps and other sources, to develop a safe path forward. This module is fortified through repeated testing and simulations that refine the mathematical modeling.
We believe the frontier for ML-based planning involves infusing closed-loop trained systems with knowledge gleaned from our expert human drivers. This critical combination enables us to scale more effectively and attain safe planner behaviors, making a safer, more comfortable ride for passengers. Just like any skill where you attain mastery, our aim is to make our robotaxi driving behavior feel intuitive and natural and appear easy, leaving our passengers free to concentrate on other things while getting around town.
We invite you to follow us on social media @motionaldrive to learn more about our work. You can also search our engineering job openings onMotional.com/careers

