Motional’s Technically Speaking series takes a deep dive into how our top team of engineers and scientists are making driverless vehicles a safe, reliable, and accessible reality. In
Part 1, we introduced our approach to machine learning and how our Continuous Learning Framework allows us to train our autonomous vehicles faster. Part 2 discussed how we are building a world-class offline perception system to automatically label data sets. Part 3 announced Motional’s release of the nuPlan dataset, the world’s largest public dataset for prediction and planning. In Part 4, Henggang Cui explains Motional’s approach to prediction, and how we use multimodal prediction models to help reduce the unpredictability of human drivers.
---------------------------------------------------
Motional’s IONIQ 5 robotaxi will be equipped with more than 30 sensors that give the vehicle a 360-degree view of everything in its environment, and a powerful onboard compute system that can detect and classify agents in real-time.
But it’s one thing for an autonomous vehicle (AV) to understand whether it’s seeing a vehicle, bicycle, or pedestrian, and another to know whether that agent is going to stay still, keep moving, or cut in front. As experienced human drivers, this is something we do routinely without thinking about it. If a car has just finished parallel parking, we give them a little extra room knowing the passenger door may open into traffic at any moment.
Through our prediction machine learning models, we can anticipate what the agents around the AV are going to do in the future. This prediction model is a critical piece of the autonomous driving stack as it allows the vehicle to react to the dynamic environment around it in a timely and safe manner.
Multimodal and uncertainty predictions
To predict the future trajectory of an agent, the model needs to understand its surrounding environment, including road geometry, as well as the position, velocity, and acceleration of other agents. To achieve this, Motional models all the agents and the map elements with a graph attention network that is processed through the vehicle’s onboard compute, which is running through models at a high update rate.
The future movement or positioning of each agent is then represented through one or multiple future trajectories, representing each trajectory as a sequence of timestamped waypoints. This process happens thousands of times every minute, ensuring the vehicle can plan a safe path based on the predicted movements of all agents around it.
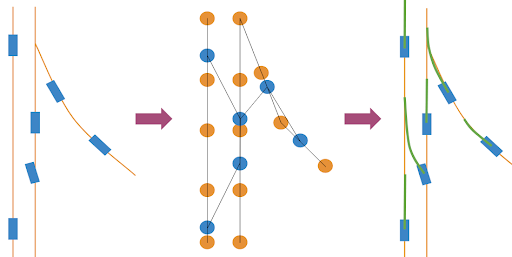
Graph attention network models the agents and map elements into a graph and learns the attention weights based on the data. Blue represents agents, orange represents lane segments, green represents predicted future trajectories of agents.
The model learns that other agents typically follow the lanes and react safely to other agents. Therefore the model can start to predict what possible directions the agent may go. However, as we know from years of experience, there is always a degree of unpredictability with human drivers and other objects we encounter on the road. We are sometimes uncertain about what other human drivers, cyclists, or pedestrians will do next. This is what makes the prediction problem such a challenge.
To account for the uncertainties, Motional’s prediction model represents possible future trajectories with a mixture of Gaussian distributions. For each agent, the model predicts multiple trajectories, along with their probabilities. As the figure below shows, this allows the model to predict multiple future outcomes that the AV should be prepared for, whereas a uni-modal prediction model often ends up predicting the average of two modes.
Within each possible agent trajectory, we represent each waypoint with a 2D Gaussian distribution, with a mean center position and a covariance matrix. This representation allows the model to predict multiple possible futures and provide confidence estimates. And as the agent, for example, gets closer to an intersection and starts to drift right, our confidence estimates will change to reflect the likelihood the vehicle will be turning right.
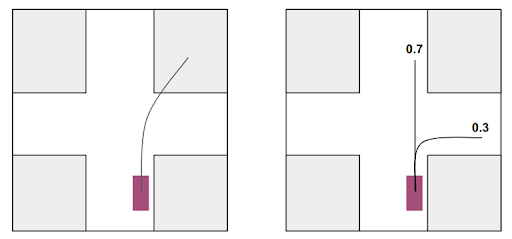
When an agent approaches this intersection, it may go straight or turn right. A uni-modal prediction model (left) often will end up predicting the average of the two modes. The multimodal prediction model (right), on the other hand, is able to predict multiple trajectories along with their probabilities.
Training prediction model with auto-labeled data
The future is inherently uncertain, which makes the prediction problem hard. But the good news is that the future also reveals itself. If we just look forward in time, we can know what every other agent actually does. Motional’s offline perception system provides us with thousands of hours of auto-labeled data that timestamps where agents were in the past as well as where they went in the future. This allows our systems to better predict how an agent may act based on how similar agents previously acted in similar scenarios.
We strongly believe in the value of sharing data to advance the larger autonomous vehicle tech community. Following up on the success of our nuScenes dataset, we are sharing part of our auto-labeled data through Motional’s nuPlan dataset, which is the world’s largest benchmark for AV planning and features 1,500 hours of auto-labeled data. We believe that the large size of this dataset helps the community further improve prediction performance.
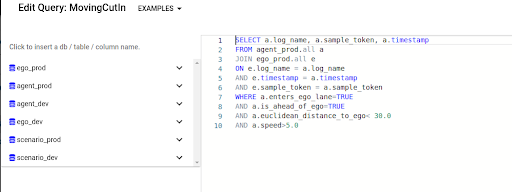
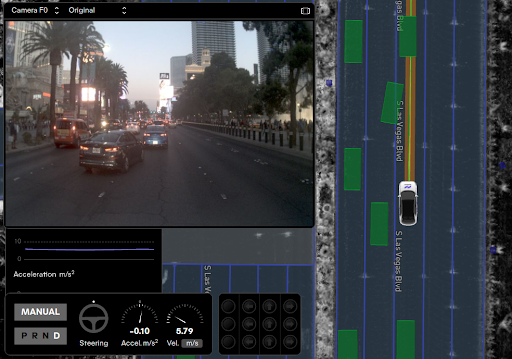
Top: A query search to find examples of a predicted vehicle cut-in. Bottom: A visualization of one example from that query.
Prediction data mining with CLF
The prediction model should be able to predict the agents’ future trajectories in not only the nominal scenarios (such as lane following and regular intersections) but also the more challenging and unusual scenarios (such as cutting-in and jaywalking). Accomplishing this requires having the right data to train on. Not only do we want a large-scale, auto-labeled dataset, it needs to be well-balanced, containing both nominal driving conditions (such as agents following their lanes), and a large number of edge cases. To achieve this, we leverage Motional’s Continuous Learning Framework (CLF) to both mine for those interesting scenarios, as well as automatically identify any scenario where the model shows high prediction errors.
The interesting scenarios that we mine are used to augment our training sets and create a targeted scenario validation set that measures prediction errors. The high prediction error scenarios are also added to our training sets. By doing this, our prediction model is able to continuously improve with every mile we drive and also adjust to changes in the operational domain - for example, when we expand into a new city.
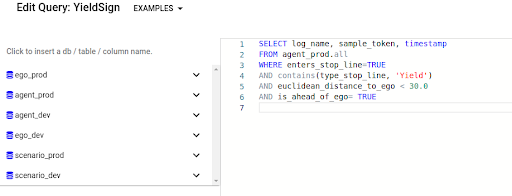
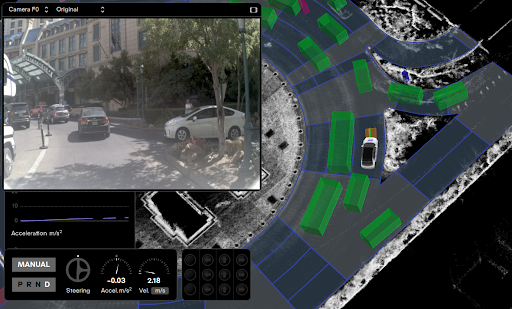
Top: A query search to find examples of agents approaching yield signs. Bottom: One visualization of an example from that query.
At Motional, we embrace a machine learning-first approach, and trajectory prediction is an important part of that ecosystem. Just like human drivers learn through experience how to anticipate the movements of other drivers, we’re creating autonomous driving systems based on machine learning-principals that improve our technology with every mile driven. Accurately predicting what other objects in the driving environment are going to do is essential to ensuring that our AVs can navigate complex streetscapes in a way that’s safe to the vehicle and everything around it.
We invite you to follow us on social media @motionaldrive to learn more about our work. You can also search our engineering job openings onMotional.com/careers

