
Consider the following scenario: an autonomous vehicle (AV) is driving the speed limit on a city road and its sensor system detects an object approaching quickly from behind.
The AV’s three sensor modules –cameras, radars, and lidar– can easily track the object as it accelerates, calculate the speed at which it’s moving, and even classify it (car vs. truck). What hasn’t always been clear is whether the approaching vehicle is an emergency vehicle or just an unsafe driver in a hurry.
Motional has developed a Second-Stage Vision Network that uses machine learning principles to add important context to our object classifications. This additional fine-grain classification then flows downstream improving our perception, prediction, planning, and control substacks.
So as the vehicle approaches, our Second-Stage Vision Network is able to identify distinct vehicle markings and flashing blue lights, determine that it’s a police cruiser, and pull over safely.
The Need For More Understanding
Motional’s IONIQ 5 robotaxi uses a multi-modal sensor package featuring cameras, long and short-range radar, and long and short-range lidar. Here is the camera and perception sensor setup that we used to capture data found in our popular nuScenes dataset. For more information see also this blog post.
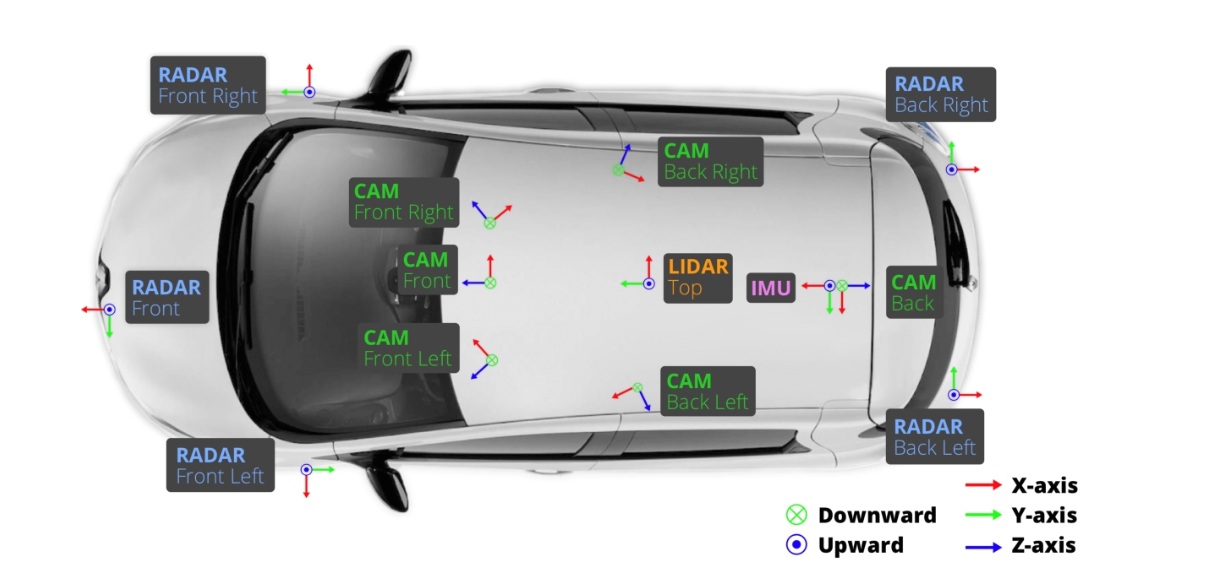
Combined together, they provide a robust, complementary, 3D portrait of the driving environment. This information, which includes directional vectors and velocities, is helpful for generating crude classifications (i.e. pedestrian vs. car vs. truck vs. traffic light).
Individually, however, the sensors can also have some limitations. For example, the light and electromagnetic pulses used by lidars and radars can’t detect colors, or which way a person is facing. Cameras are capable of detecting these details, but can lack 3D depth.
As human drivers, we understand that driving safely requires us to interpret contextual clues. For example, a pedestrian at a crosswalk will typically look towards the driver of a car to signal their intent to cross. A good human driver will see this non-verbal communication and stop at the crosswalk to let the pedestrian cross.
Traditional AV perception stacks do a good job recognizing and classifying pedestrians, but not necessarily their expressions and gestures. However, detecting and understanding these additional layers of context are essential for AVs to understand what a pedestrian may do next.
This is where Motional’s Second-Stage-Vision-Network (SSVN) comes in.
Motional’s Perception Stack
The perception subsystem is responsible for performing detection and classification tasks, and tracking objects relevant to the AV’s operational area. While humans can only focus on a few critical objects at a given time, our AVs track all relevant objects in a 360-degree range around the driving environment.
At a high level, our perception stack consists of three main modules:
- First, objects are detected in 3D using two main, parallel, machine-learning based object detectors – the Lidar Semantics Network, which operates on lidar (both short and long-range), radar, and camera data; and the Surround View Image Semantics Network, which uses camera data.
- Second, individual object detections are then connected, i.e. tracked, across time. That is, given independent detections at frames t, t-1, t-2, …, t-n the tracker identifies how an object moves from one frame to another.
- Third, each object track is used as an input for our SSVN classification network, which then extracts additional visual information for each object. The SSVN is used for a variety of fine-grained classification tasks, such as whether a pedestrian standing near a crosswalk is looking to cross the road or just engaged in conversation with a friend. We’ll go into more detail about this below.
The output of the perception stack is then passed to the downstream prediction, planning and control subsystems to act upon.
Second-Stage Vision Network (SSVN)
The Second Stage Vision Network is a separate pipeline designed to help train the vehicle to handle long-tail problems by performing fine-grained object classification.
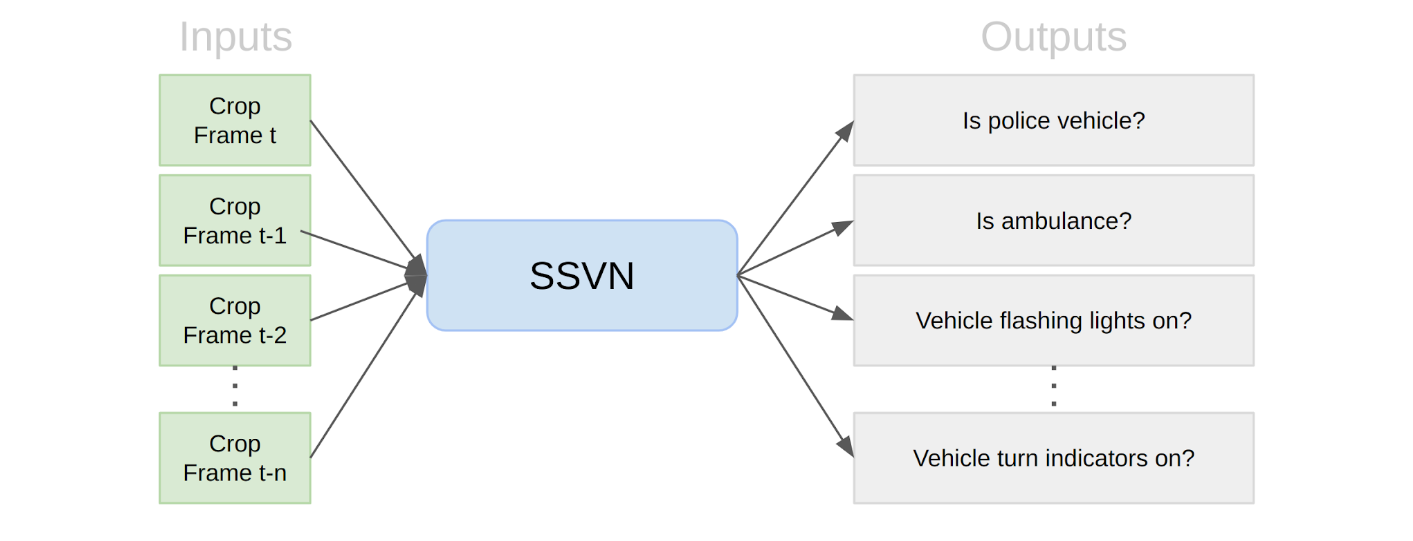
The inputs to the SSVN module are automated image crops of a given object for the last “n” frames. This is illustrated in the diagram below. Each crop is rectangular and uniform in size, e.g. 512x512 pixels. The SSVN model uses a modified ConvNet backbone to encode the input crops with certain output: Does the vehicle have flashing lights? Is there an authority figure directing traffic? What’s the shape of the vehicle? These outputs flow into independent classification heads.
Below are examples of camera-generated image crops used as inputs to the SSVN. The left-most image is at time “t”, and the image at right is “t+6”. Based on these inputs the SSVN produces an output that classifies this not as a pedestrian but a person directing traffic.

While training and evaluating the system, careful data selection is imperative to ensure the modeling learns how to handle edge cases, which are instances that happen infrequently during everyday driving. For the training set, one challenge is a data imbalance problem; during typical driving our AVs encounter way more regular vehicles than fire trucks or ambulances. We solve this data imbalance problem mainly by upsampling under-represented classes, and via smart construction of the training set. The evaluation set also needs to be sufficiently diverse so that we can reliably quantify how the model performs.
Once the SSVN model is trained, we can perform multiple iterations of “active learning” to further improve the model. For example, we mine hard-negatives via crops where the model is uncertain. We then obtain manual annotations for these crops (e.g. does a crop show an emergency vehicle or not?), and finally use that data to train the new model.
The more our robotaxis drive on public roads, the more edge cases they encounter, allowing us to build more robust data sets and refine our modeling.
Context Improves Safety
As AVs are introduced into more markets at higher volumes, they will encounter more complex situations that require additional contextual understanding to handle safely and comfortably. We can prioritize some of these longtail scenarios based on public safety, such as making sure we correctly interact with emergency vehicles, and understand the intent of pedestrians at crosswalks.
Second-Stage Vision Network (SSVN) is providing Morional’s robotaxis with fine-grain classification needed to inform the downstream perception, prediction, planning, and control substacks. By collecting data from multiple sensors, we’re able to mitigate potential failures by employing redundancy and diversity. The fine-grained analysis of the SSVN, combined with the parallel pipeline architecture of the perception stack then helps our AVs accurately understand its surroundings, predict future movements, and safely navigate complex traffic scenarios.
We invite you to follow us on social media @motionaldrive to learn more about our work. You can also search our engineering job openings on Motional.com/careers

